Introducción
El despliegue de modelos de aprendizaje automatizado abarca todo el proceso de poner modelos en un entorno de producción, donde pueden proporcionar predicciones a otros sistemas de software. Solo cuando los modelos son desplegados al entorno de producción pueden comenzar a ofrecer su valor agregado, lo que hace que el paso del despliegue sea crucial. Sin embargo, existe cierta complejidad en el despliegue de modelos de aprendizaje automático.
Este artículo pretende lograr que comprendas de dónde viene esta complejidad, y también ofrecerte herramientas y datos útiles para combatir esta complejidad. Si estás más interesado en código fuente, tutoriales paso a paso y proyectos con ejemplos, sacarás más provecho de nuestro curso Udemy Deployment of Machine Learning Models. Este artículo no está escrito para principiantes, pero no te preocupes. Podrás seguir las explicaciones si estás dispuesto a consultar los diversos enlaces proporcionados en el texto. Comencemos…
Contents
- ¿Por qué son difíciles los sistemas de Aprendizaje Automático?
- Arquitectura de los sistemas de aprendizaje automatizado
- Principios clave para el diseño de sistemas de aprendizaje automático
- Procesos de producción reproducibles
- Herramientas
- Testeo
- Despliegue
- Monitoreo y alertas
- Qué hacen los demás?
- Un entorno cambiante
1. ¿Por qué son difíciles los sistemas de Aprendizaje Automatizado?
Los sistemas de aprendizaje automatizado contienen todos los desafíos del software tradicional, sumados a una serie de aspectos específicos del aprendizaje de máquinas. Esto está bien explicado en el artículo de Google “Hidden Technical Debt in Machine Learning Systems”. Algunos de los desafíos clave adicionales incluyen:
La necesidad de poder replicar: Especialmente en sectores que son controlados por autoridades regulatorias, la posibilidad de reproducir predicciones hechas por nuestros modelos implica que la calidad de los registros (logs) de software, la gestión de dependencias, versiones, recogida de datos y los flujos de ingeniería de características, además de muchos otros aspectos, debe ser extremadamente alta.
-
Entrelazamiento: si hay un cambio en la definición de una variable, luego la importancia, los coeficientes y el uso de las demás variables también puede cambiar. Esto también se conoce como el problema “cambiar algo cambia todo”, y significa que los sistemas de aprendizaje automatizado deben ser diseñados de manera que cambios en la ingeniería de variables y cambios en el grupo de variables utilizadas, puedan ser monitoreados fácilmente.
-
Dependencias de datos: en un sistema de AA, puede haber dos componentes igualmente consecuentes: código y datos. Sin embargo, algunas entradas de datos son inestables, tal vez cambiando a través del tiempo. Usted deberá comprender y hacer un seguimiento de estos cambios para poder entender su sistema en su totalidad.
-
Configuración: especialmente cuando los modelos son iterados constantemente y cambiados de forma sutil, hacer un seguimiento de actualizaciones de configuración y mantener su claridad y flexibilidad puede ser una carga adicional.
-
Preparación de datos y características: si no los controlamos, grandes redes de scripts, uniones, scraping, y archivos de salida intermedios pueden formarse alrededor de los varios pasos de limpieza de datos (munging) e ingeniería de variables. Procesar o mantener este tipo de “código pegamento” es una tarea sumamente frustrante y proclive a errores, incluso para un desarrollador de software muy experimentado.
-
Detectar errores en el modelo: hay muchas cosas que pueden salir mal en aplicaciones de aprendizaje automático que no serán detectadas fácilmente mediante pruebas unitarias o de integración tradicionales. Desplegar la versión equivocada de un modelo, olvidar una variable, y aprender sobre un conjunto de datos obsoleto son solo algunos ejemplos.
-
Separación de experiencias: los sistemas de aprendizaje de máquinas requieren la cooperación de múltiples equipos, lo que puede llevar a que ningún individuo o equipo comprenda realmente cómo funciona el sistema en su conjunto, a que los equipos se echen culpas por los fallos, y otras ineficiencias generales.
Los sistemas de aprendizaje de máquinas comprenden varios equipos (también pueden incluir ingenieros de datos, DBA, analistas, etc.)::
Una de las razones por la cual el despliegue de modelos de aprendizaje automático es complejo es que incluso la manera en que se emplea el concepto suele ser engañoso. En realidad, en un sistema típico de despliegue de modelos de aprendizaje automático, el modelo en sí es un componente pequeño. Este diagrama del artículo mencionado con anterioridad es útil para demostrar este punto:
El modelo constituye una pequeña fracción de un sistema de AA (imagen tomada de Sculley et al. 2015):
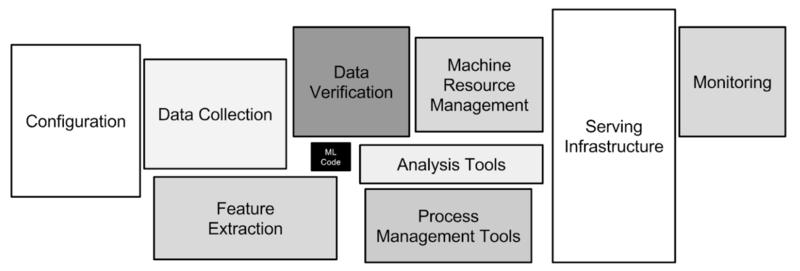
- Configuration: Configuración
- Data collection: Recolección de datos
- Data verification: Verificación de datos
- MRM: Gestión de recursos de automatización
- Serving infrastructure: Infraestructura de servicio
- Monitoring: Monitoreo
- Feature extraction: Extracción de características
- Analysis tools: Herramientas de análisis
- PMT: Herramientas de gestión de procesos
- ML Code: Código de aprendizaje automatizado
Esto significa que no es posible pensar en el despliegue del modelo de forma aislada, sino que debe ser planificado al nivel del sistema en general. El despliegue inicial no es la parte más difícil (aunque puede tener sus desafíos). Es en el mantenimiento continuo del sistema, las actualizaciones y los experimentos, las auditorías y el seguimiento que las deudas técnicas comienzan a acumularse. Es necesario reflexionar seriamente sobre la arquitectura de nuestros sistemas si queremos estar a la altura de los desafíos descritos en esta sección.
2. Arquitectura de los sistemas de aprendizaje automatizado
El punto de comienzo para la arquitectura siempre debe ser las necesidades del negocio y los objetivos globales de la compañía. Se deberá comprender las restricciones, el valor que se está creando y para quién, antes de comenzar a buscar soluciones tecnológicas. Algunas preguntas oportunas serían las siguientes:
- ¿Debe poder realizar predicciones en tiempo real (y si la respuesta es positiva, el plazo será de diez milisegundos o un par de segundos), o será suficiente poder predecir algo con 30 minutos de demora o incluso un día después que se introdujeron los datos?
- ¿Cada cuánto espera actualizar sus modelos?
- ¿Cuál será su demanda de predicciones (esto es, el tráfico)?
- ¿Con qué tamaño de muestra de datos se está trabajando?
- ¿Qué tipo(s) de algoritmos espera utilizar? (¿y son realmente necesarios?)
- ¿Está trabajando en un entorno regulado donde la habilidad de realizar auditorías es importante?
- ¿Tiene su compañía una correspondencia entre producto y mercado (product-market fit)? (esto es, ¿debería estar preparada para que el propósito original del sistema cambie radicalmente?)
- ¿Puede esta tarea realizarse sin aprendizaje automático?
- ¿Cuán grande es su equipo, y cuánta experiencia tienen sus técnicos de datos, ingenieros y DevOps?
Una vez que hayas considerado estos requisitos principales, será útil sopesar algunas de las opciones de arquitectura de nivel alto más populares para sistemas de aprendizaje automatizado. Esta lista no es exhaustiva, pero muchos sistemas pueden catalogarse dentro de esta clasificación:
Cuatro abordajes potenciales a la arquitectura de sistemas de AA:
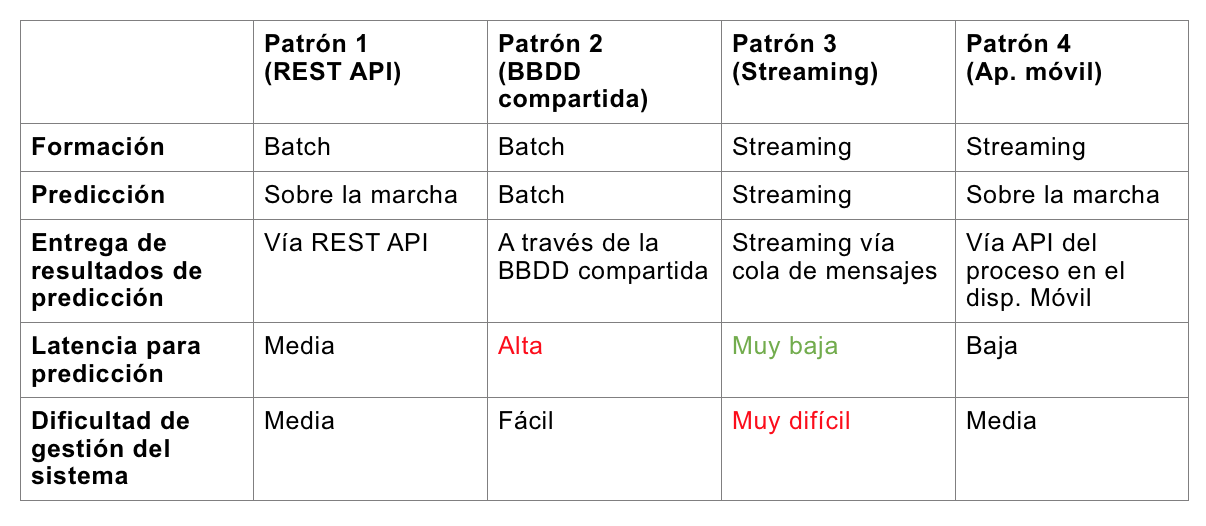
Cada una de las cuatro opciones descritas arriba tiene sus ventajas y desventajas, como se describe en la tabla. Las variaciones de los detalles pueden ser aún más significativas dentro de cada categoría principal – por ejemplo, cada una de ellas puede ser creada mediante una arquitectura basada en microservicios (con todas las características correspondientes, que ya han sido discutidas ad nauseam). Vale la pena destacar que la tercera opción normalmente requiere un diseño y una infraestructura mucho más compleja. Estos tipos de diseños se diseñan típicamente sobre alguna plataforma de streaming distribuido, como Apache Kafka. El caso 1 suele ser la mejor opción en cuanto a la relación entre desempeño y complejidad, especialmente para organizaciones sin un equipo DevOps maduro.
Un diagrama de ejemplo para un sistema de tipo 1:
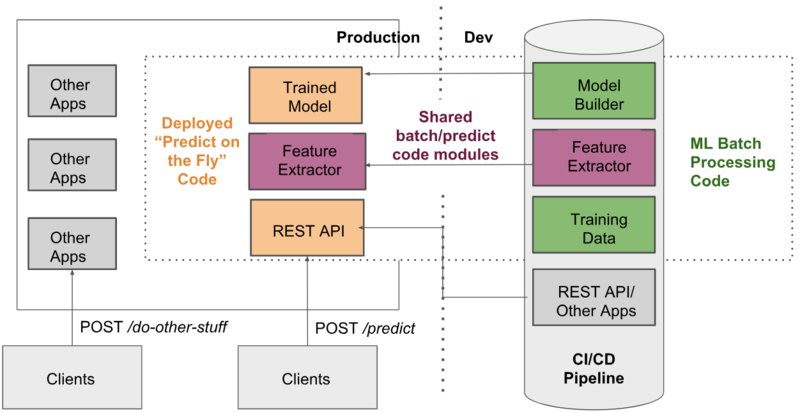
- Production: Producción
- Dev: Dev
- Model builder: Creador de modelos
- Feature extractor: Extractor de variables
- Training data: Datos de entrenamiento
- REST API/Other apps: REST API/Otras aplicaciones
- CI/CD Pipeline: CI/CD Pipeline
- Shared batch/predict code modules: Módulos de código compartido batch/predicciones
- Trained model: Modelo entrenado
- REST API: REST API
- Deployed “predict on the fly” code: Código desplegado para “predecir sobre la marcha”
- Other apps: Otras aplicaciones
- Clients: Clientes
- POST /do-other-stuff: POST /hacer-otras-cosas
- POST /predict: POST /predecir
- Code modules: Módulos de código
Elección de lenguaje
Para simplificar el proceso, es una buena práctica que el lenguaje elegido para el entorno de investigación sea el mismo que para el entorno de producción. En general, muchos sistemas utilizarán Python, debido a su rico ecosistema de ciencia y procesamiento de datos. Sin embargo, si la velocidad es una preocupación central del sistema, Python puede no ser idóneo (aunque hay muchas formas de hacer que Python sea más efectivo). Cuándo cambiar a otro lenguaje por cuestiones de rendimiento es una decisión importante. Esta decisión de cambio de lenguaje solo debe ser tomada en caso de ser totalmente necesaria, ya que la carga de comunicaciones entre los equipos de investigación y producción se vuelve pesada. Por otra parte, si todos sus técnicos de datos son experimentados desarrolladores Scala, no hay mucho de qué preocuparse.
3. Principios clave para el diseño de su sistema de aprendizaje automático
Independientemente de cómo decida diseñar su sistema, es importante tener en cuenta los siguientes principios:
- Desarrollar para la reproducibilidad desde un principio: haga persistentes todos las entradas y salidas del modelo y los metadatos relevantes como por ejemplo, configuraciones, dependencias, geografía, husos horarios, o cualquier otra cosa que podría serle útil si tuviera que explicar una predicción pasada. Preste atención a las versiones, incluso de los datos usados para entrenar el modelo.
- Procese los pasos del AA como parte de su build: esto es, automatice el entrenamiento del modelo y su publicación.
- Planifique para extender: si piensa actualizar sus modelos con regularidad, debe reflexionar cuidadosamente sobre cómo hará esto desde un principio.
- Modularidad: en la mayor medida posible, trata de reutilizar el código de preprocesamento y de ingeniería de variables del entorno de investigación en el entorno de producción.
- Testeo: planifique un tiempo significativamente mayor para probar sus aplicaciones de aprendizaje de máquinas, ya que estas requieren tipos de pruebas adicionales (más detalles en el punto 6).
4. Procesos de producción reproducibles
A medida que va cambiando desde los Jupyter notebooks del entorno de investigación a las aplicaciones listas para utilizar en el Mercado, una idea clave es la creación de procesos de producción reproducibles para sus modelos. Dentro de estos procesos, querrá incluir los siguientes elementos:
- Recolección de fuentes de datos
- Preprocesamiento de datos
- Selección de variables
- Creación de modelos
Naturalmente, es más fácil decirlo que hacerlo, en particular a lo que se refiere al paso de recolección de datos, ya que los datos suelen ser un objetivo móvil. Si la reproducibilidad es un requisito regulatorio, deberá considerar cuidadosamente algunas cuestiones como los controles y las versiones de los archivos, bases de datos, objetos S3 y otras fuentes de datos utilizadas durante el entrenamiento del modelo. Sus procesos estandarizados deberían ayudarle a colocar modelos ya entrenados y persistentes en otras aplicaciones, donde pueden ofrecer sus predicciones. Aunque es posible escribir código personalizado para este propósito (y en casos complejos, no habrá más opción que hacerlo), trate de evitar reinventar la rueda. Un par de soluciones interesantes para tener en cuenta:
Hay muchas más opciones – consulte la documentación de su entorno de aprendizaje automatizado de elección.
5. Herramientas
Contenedores
Desde la llegada de Docker en 2013, el uso de contenedores ha revolucionado la manera en que se despliega software. Los beneficios del uso de contenedores se aplican de igual manera, o incluso más, a los sistemas de aprendizaje de máquinas. La reproducción de sistemas basados en contenedores es mucho más sencilla porque las imágenes de los contenedores aseguran que las dependencias de los sistemas operativos y de los procesos del tiempo de ejecución permanezcan fijas. La capacidad de generar entornos precisos rápidamente y con consistencia constituye una ventaja significativa para la reproducibilidad durante las fases de pruebas y entrenamiento. Los contenedores también trabajan muy bien con flujos de trabajo CI/CD modernos, y tienen implicancias relacionadas con el escalado que describiré más adelante en la sección 7.
Resumen: Desarrolle su sistema de aprendizaje de máquinas para que todas sus partes (incluyendo el entrenamiento del modelo, pruebas y servicios) puedan ser aplicadas mediante contenedores.
CI/CD
Muchos científicos de datos y personas que provienen del sector académico no se dan cuenta de lo importante que una serie de herramientas y procesos de Integración y despliegue continuos puede ser para mitigar los riesgos de los sistemas de AA. Para los que se preguntan si realmente es tan importante CI/CD, recomiendo consultar The DevOps Handbook por Kim et al. En el contexto de los sistemas de aprendizaje automatizado, tener todos los aspectos del proceso, incluso la formación y las pruebas, integrados como parte del testeo y despliegue automático llevará a resultados mucho más eficaces – siempre y cuando estés desarrollando las pruebas de la forma adecuada… (ver sección 6). También puede ser muy útil para la creación de registros de auditoría.
Estrategias de despliegue
¡No alcanza con simplemente arrojar su modelo a producción! Explore las diferentes maneras que existen para desplegar su software, con despliegues del tipo sombra (“shadow mode”) y canario siendo de particular interés para aplicaciones de AA. En el modo sombra, se capturan las entradas y predicciones de un nuevo modelo en producción sin realmente servir esas predicciones. Así podrás entonces analizar los resultados sin tener que afrontar consecuencias si se encuentran problemas. A medida que tu arquitectura madura, podrás habilitar las distribuciones graduales o “canario”. Esta práctica se basa en la servir el modelo solo a una pequeña fracción de clientes. Esto requiere una instrumentación más madura, pero minimiza los errores cuando estos ocurren.
6. Testing
Si usted no es un ingeniero de sistemas, puede considerar que las pruebas son “útiles”. Esto es totalmente incorrecto. Las pruebas son cruciales.
Sin embargo, las pruebas comunes unitarias/de integración/de aceptación no son suficientes para los sistemas de aprendizaje automatizado. Además de estas pruebas, vale la pena expandir el repertorio de herramientas para incluir:
-
Pruebas diferenciales: la comparación de las predicciones promedio/por observación proporcionadas por un nuevo modelo contra un modelo antiguo para un mismo conjunto de datos estándar. Deberás modificar la sensibilidad de estas pruebas dependiendo de los casos de uso del modelo. Estas pruebas pueden ser cruciales para detectar errores en modelos que parecen saludables e íntegros, por ejemplo, cuando se ha utilizado un conjunto de datos antiguo para entrenar el modelo, o se ha eliminado una característica accidentalmente desde el código de selección de características. Este tipo de problemas, que son específicos del aprendizaje de máquinas, no son detectados por las pruebas de software tradicionales. Aún más, sin pruebas diferenciales efectivas, puede que no se percate de este tipo de errores hasta que hayan causado un daño significativo. Lo último que queremos es tener que explicarle este tipo de errores a un organismo regulador.
-
Pruebas de referencia: estas pruebas comparan el tiempo necesario para entrenar o para servir las predicciones desde una versión del modelo a otra. Previenen la introducción de código fuente ineficiente en sus aplicaciones de aprendizaje automatizado. Una vez más, esto es algo que es difícil de detector mediante métodos de testeo tradicionales (aunque algunas herramientas de análisis de código estático pueden ayudar). Si está trabajando con Python, vale la pena tener en cuenta la biblioteca pytest-benchmark.
-
Pruebas de carga y tensión (load/stress): Estas pruebas no son realmente específicas del aprendizaje automatizado, pero debido a las demandas excepcionalmente grandes de algunas aplicaciones sobre CPU/memoria, este tipo de pruebas son valiosas para nuestros entornos.
Todas estas pruebas son más fáciles de aplicar con aplicaciones basadas en contenedores, ya que es mucho más sencillo crear un entorno de pruebas realista.
7. Despliegue
No hay nada en esta sección que no sea aplicable también a cualquier sistema convencional que no contiene aprendizaje automatizado. No trates de reinventar la rueda con tus despliegues de aplicaciones de aprendizaje automatizado; las prácticas ya establecidas te ahorrarán muchos problemas. Para los despliegues, deberás decidir si tomarás el abordaje Plataforma como servicio (PaaS) o Infraestructura como servicio (IaaS).
Un PaaS puede ser muy útil para prototipos y negocios con poco tráfico. Eventualmente, una vez que el negocio y/o tráfico crece, deberás tomar un abordaje más complejo mediante IaaS. Existen variadas soluciones de los actores principales (AWS, Google, Microsoft), además de una amplia gama de opciones de nicho que esperan que Jeff Bezos no los elimine del mercado. Si nunca ha desplegado algo antes, recomiendo comenzar con Heroku.
Si sus aplicaciones usan contenedores, los despliegues tienden a ser más fáciles en la mayoría de las plataformas/infraestructuras. Trabajar con contenedores también te da la opción de usar una plataforma de orquestación de contenedores (Kubernetes es el estándar actual) para escalar rápidamente el número de contenedores a medida que cambia la demanda. Asegúrate de que tus despliegues ocurran mediante una plataforma de “despliegue continuo”.
Un ejemplo de una serie de componentes involucrados en el ciclo de vida de un despliegue:
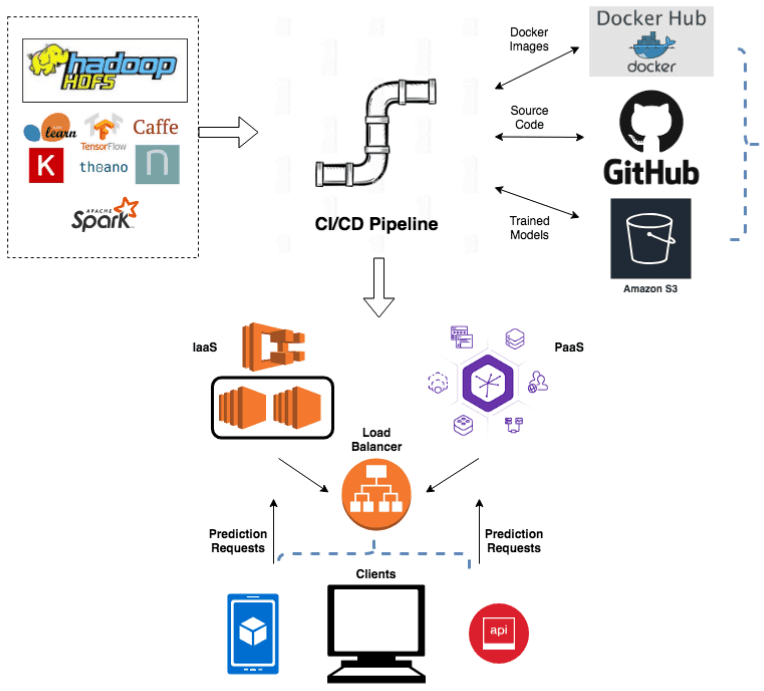
8. Monitoreo y alertas
Estos aspectos no son exclusivos del aprendizaje automático, pero el monitoreo y las alertas pueden ser muy importantes al desplegar tus modelos. A medida que tu sistema crece en complejidad, requerirá capacidades de monitoreo y alertas para saber cuándo las predicciones para un sistema en particular están fuera del rango esperado. Monitoreo y alertas también está relacionado con problemas tangenciales, como por ejemplo cuando el entrenamiento de su flamante red neuronal convolucional consume su presupuesto mensual de AWS en 30 minutos.
Querrás tener paneles de control para verificar a simple vista las versiones de los modelos desplegados y en ejecución en India y China. Existen muchas herramientas, de pago y de código abierto, que te ayudarán a realizar este tipo de tareas, y no importa tanto cuál utilice, siempre y cuando se tome el tiempo de configurar la solución elegida para lograr una visibilidad total del sistema. Una y otra vez he visto este tipo de sistemas de monitoreo y alertas implementados solo después de que algo ha salido mal.
9. Qué hacen los demás
El hecho de que muchas de las grandes compañías hayan creado sus propias plataformas para el despliegue de soluciones de aprendizaje de máquinas indica que es un tema complejo. Considere los siguientes ejemplos:
- La plataforma de Uber se llama Michelangelo
- Facebook tiene FBLearner Flow
- Google tiene TFX
- Databricks creó MLFlow
Claramente, la creación y el despliegue efectivo de sistemas de aprendizaje automatizado son difícil. Aunque es relativamente sencillo empaquetar un modelo detrás de una API Flask RES, es el mantenimiento continuo, los ajustes iterativos y la carga regulatoria que traen consigo las verdaderas dificultades.
10. Un entorno cambiante
Las plataformas, herramientas y entornos para trabajar con aprendizaje automático evolucionan rápidamente. Algunas áreas interesantes para prestar atención:
- Kubeflow intenta simplificar el aprendizaje de máquinas en Kubernetes. Es todavía relativamente nuevo, lo que significa que conlleva bastante riesgo, pero permite a equipos más pequeños y con menos experiencia en DevOps orquestar complejos ecosistemas de contenedores para tareas relativas al aprendizaje automatizado.
- El crecimiento de soluciones sin servidor, con la mayoría de los grandes actores involucrados (Azure Functions, Google Cloud Functions, AWS Lambda), en combinación con APIs ML bajo demanda provistos por las mismas compañías.
- Más maneras de cerrar la grieta entre el entorno de investigación y el de producción: en Netflix, por ejemplo, han invertido un esfuerzo significativo para poder usar Jupyter notebooks para tareas de producción.
- Más compañías creando soluciones que se enfocan en los temas desarrollados en este artículo – rotulación y versionamiento de datos, pruebas de modelo automatizadas, validaciones y gestión del ciclo de vida.
- Aprendizaje de máquinas del lado del cliente con TensorFlow.js. Esto es todavía muy prematuro, y no es claro cuán cómodas estarán las compañías grandes con el código de sus modelos disponible para su lectura por la competencia.
- El crecimiento de los sistemas de aprendizaje automático “en tiempo real”, en los cuales los modelos se actualizan constantemente a medida que nuevos datos ingresan. Esto se debe en parte a la posición que ha logrado establecer Apache Kafka, aunque hay otras alternativas interesantes cobrando más importancia, como Apache Pulsar.
En resumen, todo el espacio de despliegue de aplicaciones de aprendizaje automatizado y la gestión de su ciclo de vida se verá probablemente muy diferente en unos pocos años. En estos tiempos, poco debería sorprender…