Transcribing Audio mp3 files with Python and OpenAI's Whisper Model
An introduction to using the Whisper automatic speech recognition (ASR) system
Introduction
Whisper, an advanced automatic speech recognition (ASR) system developed by OpenAI, is changing how we transcribe audio files. Offering unparalleled accuracy and versatility, it can handle various languages and audio qualities and is completely open-source with a permissive MIT licence.
This makes Whisper not just a technological marvel, but a practical tool for professionals and enthusiasts alike. If you’re involved in any project requiring programmatic audio transcription (as opposed to just using chatgpt), Whisper’s efficiency and accuracy will impress you. As if that wasn’t enough, setting it up is super easy…
Installation
I was only able to get the install to work via the latest git commit: pip install git+https://github.com/openai/whisper.git. This was true
with pip and also with poetry meaning my pyproject.toml ended up looking like this:
[tool.poetry.group.dev.dependencies]
openai-whisper = {git = "https://github.com/openai/whisper.git"}
Since I am on MacOS, I also had to install ffmpeg via homebrew:
brew install ffmpeg (it’ll be different on Linux/Windows - see the docs)
That’s it - after those two lines you’re ready to go.
Using Whisper via Python Script
As per the docs:
There are five model sizes, four with English-only versions, offering speed and accuracy tradeoffs
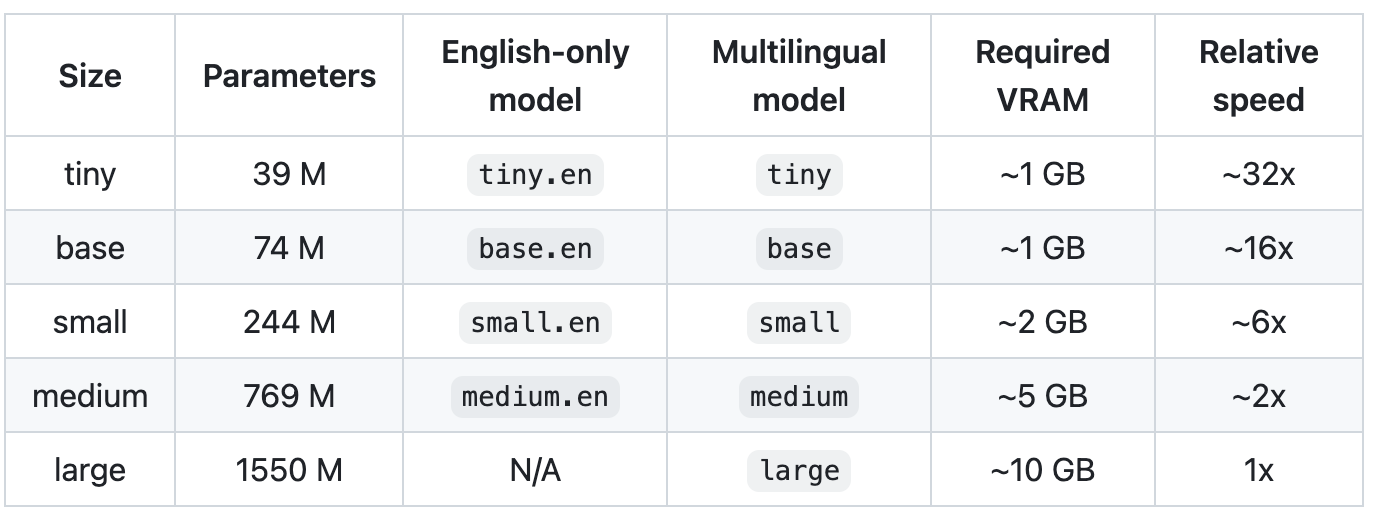
I started off using the tiny model just to test things out. Your Python scripts will involve two steps:
- Load the model
- Run your transcription
That’s it! Everything runs locally, no third-party API call required.
Here’s a basic tutorial:
import whisper
from pathlib import Path
import json
model = whisper.load_model('tiny')
path = Path('audio.mp3')
result = model.transcribe(str(path), language='en', verbose=True)
# Dump the results to a JSON file
with open('transcript.json', "w") as file:
json.dump(result['text'], file, indent=4)
I’m writing to a JSON file, but you could just as easily write to a txt file.
Setting verbose=True shows you the text being transcribed in the console.
- If set to
True, it displays all the details, - If set to
False, minimal details are shown. - If set to
None, does not display anything.
The object returned by the model.transcribe method is a dictionary containing the resulting text (“text”) and
segment-level details (“segments”), and the spoken language (“language”). The segments are valuable because they
allow you to capture timestamped transcript information.
The spoken language of the audio can also be autodetected, but I’ve heard you get better performance if you specify
the language via the language parameter.
How Good Is Whisper?
Whisper’s performance varies widely depending on the language, and their docs have some striking graphs showing the discrepancies:

I’ve only used the Whisper speech recognition model with English audio, and have found the following:
tinymodel: Good for rapid prototying, but often makes errors and misses words.smallmodel: Really good speed to quality ratio, good enough for a lot of use casesmediummodel: Excellent quality, the only thing it really makes mistakes on are names of people/places/companies and very occasionally slang words.
You can correct the typical mistakes around naming by providing an initial_prompt argument to
Whisper’s transcribe method like so:
prompt = (
f"This is a podcast audio file which talks about baseball. The"
f"interview subject is Joe Bloggs and the interviewer is Jim Bloggs.")
result = model.transcribe(str(_file), language='en', verbose=True, initial_prompt=prompt)
Certainly for English use-cases, if you use the medium sized model with a good prompt your quality level is going to be excellent.
You will of course need significant RAM on your machine, so if you’re doing this in the cloud it might be easier just to use
the OpenAI API for speech-to-text transcription.
Usage in a Django Custom Command
I am using Whisper in a Django project, so here’s a bonus Python snippet to show you how to run it in a Django custom command:
import json
from pathlib import Path
import whisper
from django.core.management.base import BaseCommand
class Command(BaseCommand):
help = 'Transcribe audio with whisper'
def add_arguments(self, parser):
parser.add_argument('--directory', type=str, help='The directory where the audio files are.')
parser.add_argument('--model', type=str, help='Whisper model size', default="tiny", required=False)
def handle(self, *args, **options):
directory = options['directory']
size = options['model']
self.stdout.write(f"Using model size: {size}")
model = whisper.load_model(size)
path = Path(directory)
# Find all .mp3 files in subdirectories
audio_file_paths = path.rglob('*.mp3')
for _file in audio_file_paths:
transcript_file = _file.parent / f"transcript_{_file.stem}.json"
segment_file = _file.parent / f"segments_{_file.stem}.json"
# Check if both transcript and segment files exist
if transcript_file.exists() and segment_file.exists():
self.stdout.write(f"Skipping transcription for file: {_file}, transcript and segments already exist.")
continue
self.stdout.write(f"Transcribing file: {_file}")
prompt = (
f"This is a podcast audio file which talks about baseball. The"
f"interview subject is Joe Bloggs and the interviewer is Jim Bloggs.")
result = model.transcribe(str(_file), language='en', verbose=True, initial_prompt=prompt)
with open(transcript_file, "w") as file:
json.dump(result['text'], file, indent=4)
with open(segment_file, "w") as file:
json.dump(result['segments'], file, indent=4)
self.stdout.write(f"Transcript created for file: {_file.name}")
Kick this command off with: python app/manage.py transcribe_podcasts --directory=/path/to/django/project/app_name/audio_files/ --model=tiny
This is useful for offline processing jobs, and could easily be incorporated into an asynchronous task queue workflow.
Conclusion
Whisper by OpenAI presents a powerful tool for transcribing audio files, especially in Python environments. Its varying model sizes cater to different needs, balancing speed and accuracy. While it excels in English, its performance in other languages can suck. Integrating Whisper into Django or other Python-based applications is straightforward (much more so than other LLMs) and adds significant value to projects requiring audio transcription. As recently as a couple of years ago this would have been an extremely challenging engineering task. Now it’s an hours work. The future is here.