Observability for Generative AI
Is There Anything New Under the Sun?
Disclaimer: I work on Pydantic Logfire, but these opinions are my own.
Table of Contents
Introduction
1. Non-Determinism: Same Roots, Different Scale of Impact
2. Multi-Step Agentic Behavior vs. Single-Pass Predictions
3. Observing Retrieval-Augmented Generation (RAG)
4. Embedding Analysis & Visualization for Drift and Performance
5. Multi-Modal (Video, Image, Audio, and Beyond)
6. Security & Compliance
7. Monitoring LLM Costs
Implications & Predictions
Introduction
Neckbeards are fond of leaning back and loudly opining: “In tech, there’s nothing new under the sun”.
Well, I’m not so sure.
Way back in 2020, I wrote a popular post about monitoring machine learning systems. The gist was that data drift, feature staleness, reproducibility requirements and unpredictable inputs made things trickier than standard software observability. Now, with generative AI, many of those headaches intensify, and new ones appear.
But is AI observability really that different? The short answer is: Yes.
Summary of Key Observability Challenges Pre-2020 ML vs. GenAI
| Aspect | Pre-2020 ML Systems | GenAI/LLM Systems |
|---|---|---|
| 1. Non-Determinism | Single-pass predictions, smaller range of possible outputs; each model had a single task | Highly non-deterministic, multi-task outputs from one LLM; small prompt changes can yield wide differences |
| 2. Agentic Behavior | Usually a fixed pipeline with limited logic | Dynamic chain-of-thought and tool calls, risk of infinite loops or emergent behaviors |
| 3. Observing RAG | Single retrieval step; narrower knowledge bases | RAG is mainstream; multiple retrievals feed the LLM, needing unified logs to debug hallucinations |
| 4. Embedding Analysis | Embeddings for classification; occasional PCA/t-SNE for drift checks | Heavy embedding use (RAG), advanced reduction (UMAP) for drift and new-cluster detection |
| 5. Multi-Modal | Often siloed pipelines for text, images, or numeric data | Unified pipelines (text, image, audio, code); more data volume, each with distinct drift concerns |
| 6. Security & Compliance | Typical data privacy checks; simpler logs | Heightened risk of injection, agent misuse, or PII leaks; heavier logging & redaction |
| 7. Monitoring LLM Costs | Smaller models, fewer passes, lower cost risk | Agentic calls inflate token/API usage; real-time tracking prevents surprises |
GenAI exacerbates some of the “old school” observability challenges, introduces entirely new categories of problems and also adds new techniques to our observability toolbox. This post explores the details and implications of this statement.
note: I’m deliberately not discussing running AI inference servers (i.e. model hosting) or fine-tuning models - each of which is complex and would warrant its own post. This is about running AI applications, or applications that leverage GenAI.
1. Non-Determinism: Same Roots, Different Scale of Impact
Older NLP vs. LLM-based Apps
Pre-2020 NLP
You might have had large black-box models (e.g., RNN or CNN classifiers, maybe BERT-level encoders) that
produced non-deterministic outcomes for open-ended text. But typically, each model was built to do a
single specialized task, like sentiment detection, named entity recognition, or QA on a narrow domain.
LLMs Today (mid 2020s)
A single model often handles many tasks via prompting: classification, multi-step reasoning,
generation, retrieval, etc. It can spontaneously produce a wide variety of outputs: some entirely correct,
some partially correct, and some total hallucinations. These outputs depend on user input, system instructions,
model config, or minor context changes rather than just code.
All trends point to this complexity only continuing to increase, with (by current standards) “complex” AI calls of over 500 tokens dominating traffic as per the Portkey 2025 report, which analysed over 2 trillion tokens:
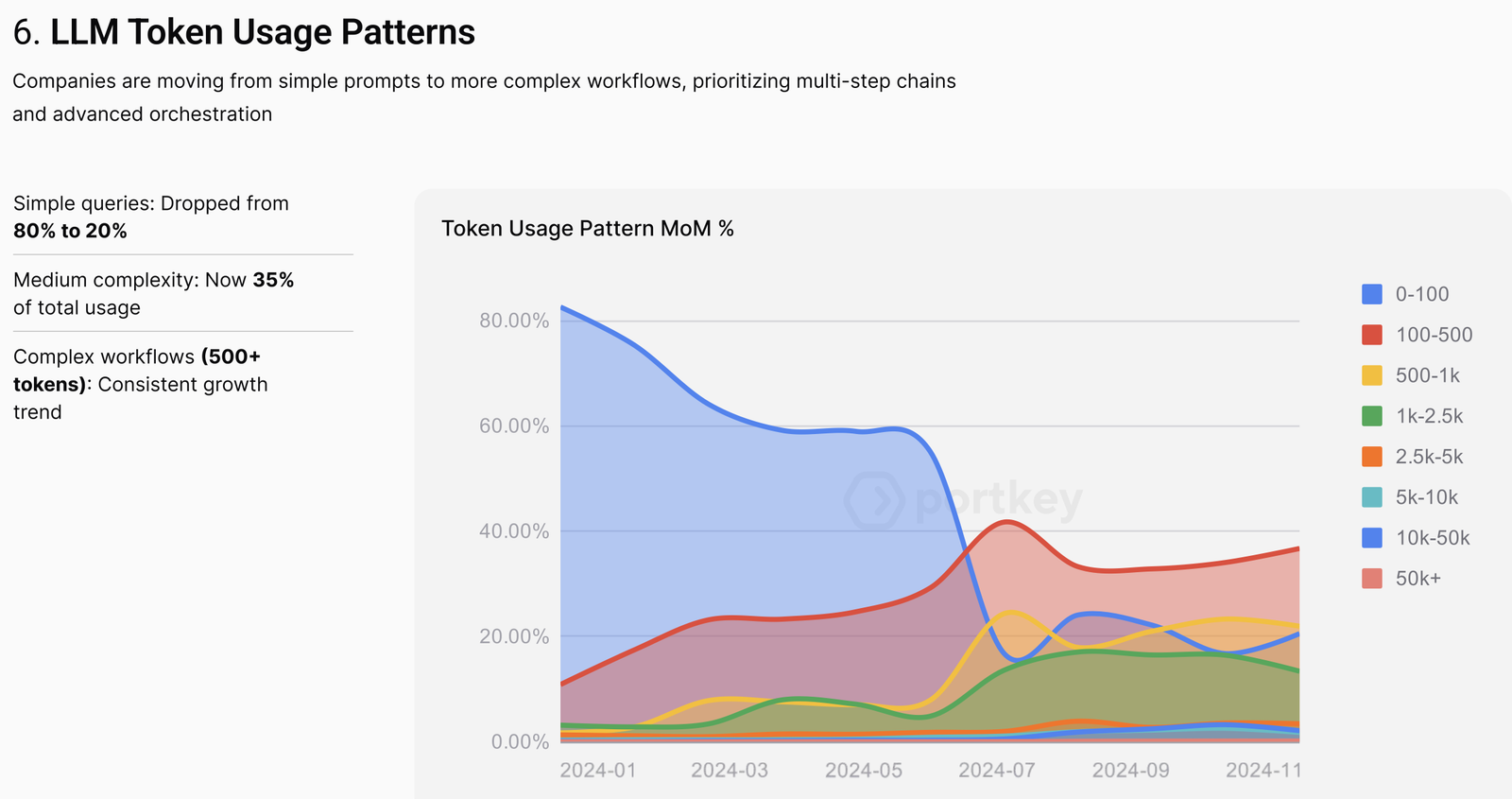
Implications for Observability
- While non-determinism itself isn’t new, the range of possible tasks and outputs from a single LLM is larger than older NLP pipelines, which were narrower and more fixed.
- New types of risks emerge with higher levels of non-determinism, the best observability tools will offer ways to detect inaccurate responses, hallucinations and toxic content
- Because LLMs can tackle different tasks in one deployment (e.g., code generation, legal summaries, multi-hop Q&A), their potential for unexpected or partial failures is higher.
- Monitoring must become more fine-grained to pinpoint whether the model is failing at code generation vs. domain-specific reasoning vs. retrieval, etc. Logging or tracing each request can’t be one-size-fits-all anymore. This is even more true with tool use in agents, which we’ll come to next.
The good news is that LLMs can help with these areas, and AI usage in observability tools is almost certainly going to increase to offer techniques like using a different LLM to detect hallucinations, bias, toxic content, inaccurate answers and irrelevant content. Modern observability tools are starting to incorporate these capabilities.
DB calls traced after LLM API call in Pydantic Logfire
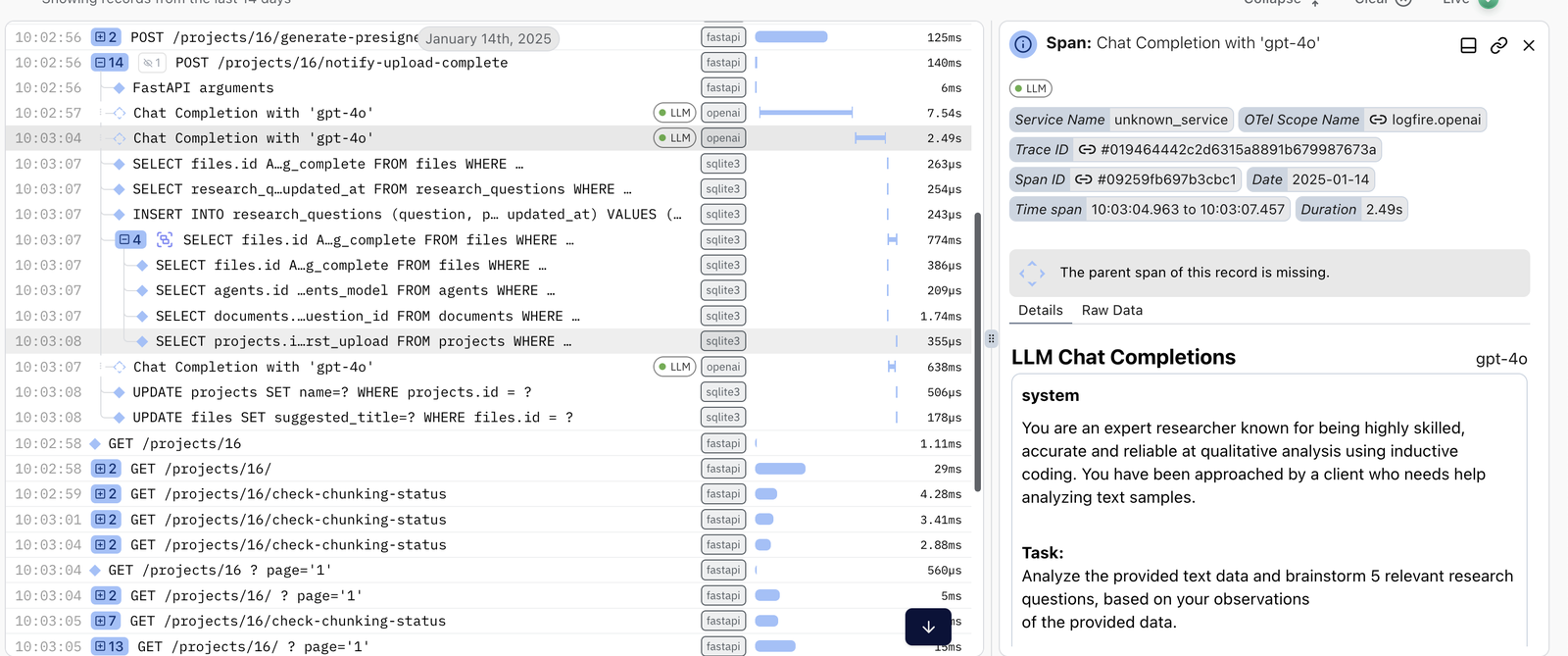
2. Multi-Step Agentic Behavior vs. Single-Pass Predictions
Traditional ML Models
- Typical Flow: A single model pass or a fixed multi-step pipeline (e.g., a
regex-based preprocessor → sentiment model → postprocessor). - You still tracked pipeline stages, but each stage was fairly static. If something broke, you usually checked input distribution or data drift for that specific stage, or compared production predictions to offline metrics.
LLM Agents Today
Despite being called many times before, it does appear that 2025 is the year of agents, which have a particular set of challenges:
- Dynamic Chaining: Systems like ChatGPT can chain multiple calls, including the use of “tools” — retrieving documents, interpreting code, running external APIs, gathering more context, then producing an answer. The LLM dynamically decides on the next step.
- On-the-Fly Revisions: Models can self-correct or revise plans mid-execution (e.g., ReAct, Reflexion approaches). This is far more dynamic than older NLP pipelines, which typically had a fixed set/order of modules.
- Emergent Abilities
Larger models can exhibit surprising new behaviors like chain-of-thought reasoning, code generation, or domain reasoning that smaller models never did. This unpredictability opens the door to entirely new failure modes:- Agent Tools Misuse: Repeated or spurious external calls that cost money or cause side effects - particularly if tools have the ability to write data, send emails or make purchases! This misuse can be by accident or also because of new types of security threats which are discussed later in this post.
- Confidently Wrong: Multi-task usage might mean the model is excellent in one domain, bizarre in another
- Chain-of-Thought Errors: A single wrong premise can derail many subsequent steps
- Partial Completions / Stuck Loops: The LLM might “hang” or keep calling a tool without progress
Why This Matters for Observability
- You need more than just top-level prediction logs — each step of the chain, particularly calls to external tools must be captured in detail, as well as older conversations that make up the entire context history. Surfacing all these elements together is key.
- For tools that have side effects - writing data, sending emails, making purchases - details of these actions are key for debugging, but also for compliance e.g. SOC2, ISO 27001 plus a host of domain-specific regulatory requirements.
- Observability must detect potential infinite loops or repeated tool calls.
- “Confidently incorrect” outputs require logs that show exactly where the chain-of-thought derailed.
- Instead of just comparing predicted labels, you might be comparing entire paragraphs, code blocks, or multi-step action sequences.
- Being able to correctly instrument agent frameworks such as LangChain, LangGraph, Llama Index and PydanticAI becomes essential.
Tool calls in langsmith
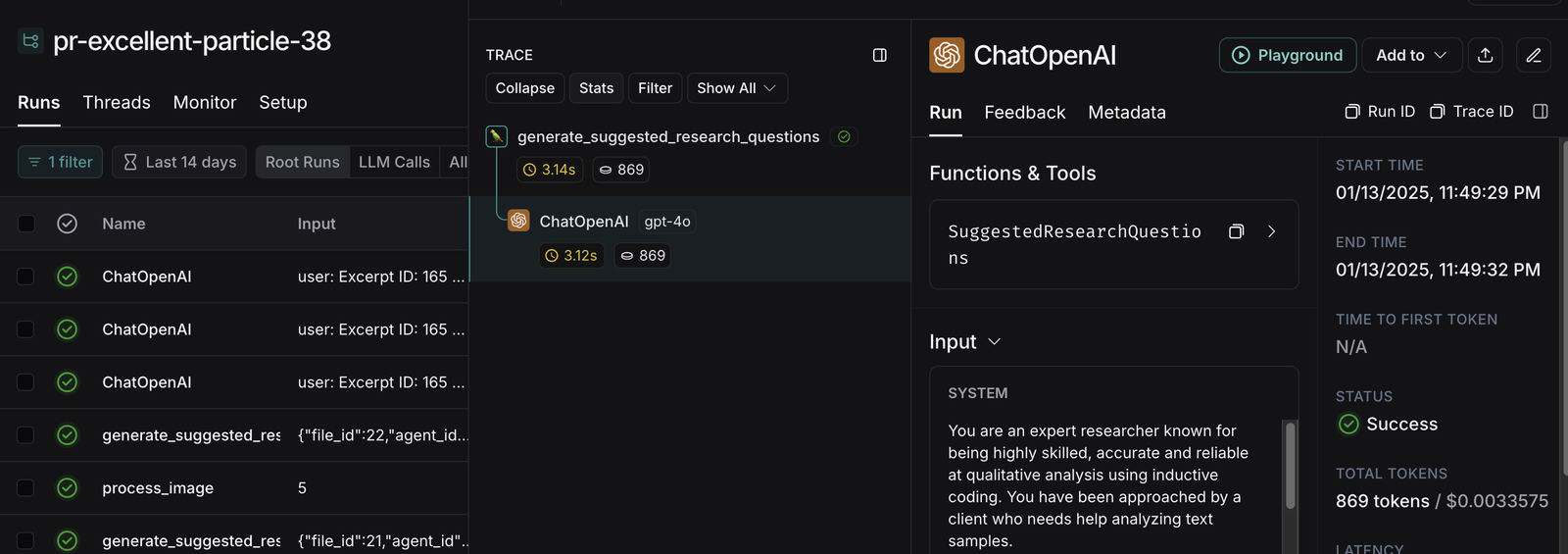
3. Observing Retrieval-Augmented Generation (RAG)
Then vs. Now
-
Older Retrieval-Based Models
Some question-answering systems or semantic search setups already used a knowledge base. But typically, it was a single pass: retrieve text, feed it to a classifier or QA model, done. -
RAG in Modern LLMs
Systems now embed user queries (and sometimes documents) into vector spaces, search top matches in a vector DB, then feed that retrieved context back into an LLM for final generation. The LLM might do this multiple times in one conversation.
Why This Matters for Observability
- Monitoring Both LLM Calls and DB/Index Health
If retrieval fails or returns stale results, the LLM may hallucinate. Observability must unify logs from retrieval calls plus the final generation. - Coupled Errors: If the retrieval step is inaccurate or incomplete, the LLM’s generation will degrade. Yet the LLM might confidently produce a final answer anyway. Debugging that requires you to see both the retrieval logs and the model logs — was the best passage missing from the top-k results or was the LLM ignoring it?
- Versioning and Consistency
Watch index versions. Was the user’s query vector computed with the updated or older embedding model? A mismatch can degrade retrieval. - Context Window and Token Budget
The LLM might only include some retrieved docs in the final prompt. Observability should capture which subset made it into the context. - Real-Time vs. Offline Data
If new docs are ingested in real time, any failure in embedding or indexing can result in incomplete or missing context.
Dynamic Multi-Hop: The LLM might query once, realize it needs more context, then query the vector DB again. Observability must correlate each retrieval call to the chain-of-thought step.
Hallucination Detection in Arize
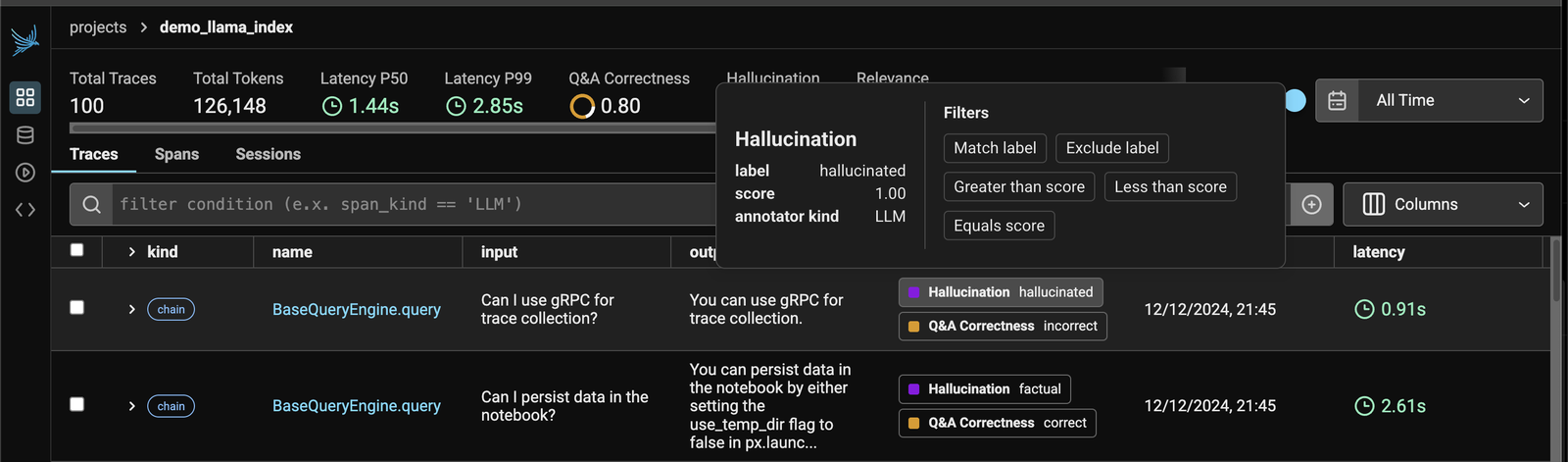
4. Embedding Analysis & Visualization for Drift and Performance
Traditional ML Embedding Challenges
- Basic Feature Embeddings: Even pre-2020 ML systems used learned representations (e.g., word embeddings). Occasionally, teams ran dimensionality-reduction methods (like t-SNE) to see if new data was shifting away from training distributions.
- “Feature Drift” Focus: Typical drift root cause analysis concentrated on whether features fed into the model had changed distribution. If so, we’d worry about model accuracy, requiring re-training or updates.
New LLM-Specific Embedding Challenges
- High-Dimensional Embedding Spaces: Modern LLMs generate large embeddings for tasks like retrieval-augmented generation (RAG) and semantic search. These embedding spaces can shift quickly if the underlying model or data changes.
- Frequent Re-Indexing: When new data arrives, or the embedding model is updated, vector indexes must be re-created or incrementally updated. That versioning must be tracked carefully—otherwise, older embeddings may not align with newer queries.
- Multi-Modal/Domain Embeddings: A single LLM might produce embeddings for text, code, audio or images (depending on the model). Each domain can drift in distinct ways.
Implications for Observability
- Ongoing Embedding Drift Detection: Observability should include monitoring distribution changes in these large embedding spaces. Tools like UMAP or t-SNE help visualize drift or newly emerging clusters.
- Index/Model Versioning: Storing the specific embedding model version and index version used at inference time is crucial. Observability systems must be able to correlate which model or index led to a certain retrieval or output.
- Cluster-Level Metrics: Instead of just top-level metrics, you’ll need to watch specific clusters for anomalies or high-error regions, enabling targeted debugging or re-training.
Embedding cluster analysis in phospho AI
5. Multi-Modal (Video, Image, Audio, and Beyond)
Traditional ML and Multi-Modal
- Narrowly Focused: Legacy systems often dealt with one or two data types (e.g., text + numeric data). Computer vision or speech recognition use cases existed but were usually siloed and had dedicated monitoring pipelines separate from text-based tasks.
- Simple Integration: Where multi-modal ML existed, it might combine an image model with a small NLP component. Observing that pipeline was typically done via separate logs (e.g., image processing logs vs. text logs).
GenAI and Multi-Modal Expansion
- Unified Models: Cutting-edge models can handle text, images, video, and audio in a single system. This can include everything from summarizing a video transcript to generating alt-text for images, sometimes in the same pipeline.
- Complex Embeddings: Multi-modal embeddings merge different feature representations (e.g., text tokens with pixel or waveform embeddings). Large changes in any modality can degrade performance.
- Increased Data Volume: Video frames or audio chunks generate far more data than text alone. This explosion of data, along with specialized transforms (e.g., spectrogram generation for audio), increases the complexity of logging and tracing.
- Diverse Failure Modes: Image or video classification might fail even if the text-based steps succeed, or vice versa. Audio transcription might degrade due to noise, but the text-based retrieval steps might still appear fine. Debugging requires coordinated logs across all modalities.
Observability Implications for Multi-Modal
- Cross-Modal Context: When an LLM references an image or uses audio input, you need to capture which exact frame or audio snippet was used, plus how it was transformed or embedded.
- Performance & Latency: Audio/video ingestion can be more resource-intensive. Observability should measure both model performance (e.g., classification accuracy) and infrastructure usage (GPU/CPU utilization) across all modalities.
- Embedding Distribution Drift: Multi-modal embeddings can drift in more complex ways than purely text-based embeddings. Visual data distribution can shift (e.g., lighting, angles), or audio data can change (e.g., new accents). Ongoing drift detection is crucial.
- Versioning & Pipelines: Because multi-modal applications often rely on a chain of specialized components (e.g., speech-to-text model, then text-based LLM reasoning, then image classification), each component must be versioned, logged, and correlated for debugging.
6. Security & Compliance
Traditional ML Security & Compliance Challenges
- Adversarial Attacks: Traditional ML models (e.g., image classifiers) faced adversarial inputs—images subtly altered to fool the model’s predictions.
- Data Poisoning: Attackers could inject incorrect data into training pipelines, causing degradation or malicious model behaviors.
- Model Theft and IP Concerns: Sensitive models needed to be protected from extraction or reverse-engineering.
- Regulatory & Industry Standards: In highly regulated environments (finance, healthcare, etc.), auditing was mandatory.
Explainabilityoften meant showing which data went into the model - Model Versioning & Traceability: Teams had to maintain metadata (model versions, training data timestamps) to verify predictions and compliance with audits. The ability to reproduce a prediction was key.
New GenAI Security & Compliance Challenges
- Prompt Injection & Code Execution: LLMs can be manipulated by cleverly crafted prompts, bypassing safeguards or tricking the model into malicious behaviors.
- Agents & Tool Misuse: Multi-step “agentic” systems can call external APIs (like writing files or sending emails), expanding the risk of inadvertent data exposure or damage. LLMs are extremely gullible and this is a big problem for security, particularly if agents have the ability to perform a harmful actions when misled.
- Larger Attack Surface: LLM-based chat interfaces are more open-ended and interactive, making it easier for attackers to discover vulnerabilities.
- Real-Time Data Poisoning: Continuous ingestion of user data (for embeddings or fine-tuning) risks faster, more damaging data attacks, potentially altering outputs on the fly.
- Chain-of-Thought & Sensitive Data Leaks: LLM transcripts (especially multi-hop contexts) can accumulate private or personal info, raising privacy and compliance issues.
- Reputation Damage from Hallucinations: Offensive or misleading statements can go viral, harming brand trust.
- Embedding-Driven Data Use: Storing user data in embeddings doesn’t always ensure anonymity. Under GDPR-like laws, these embeddings can still be considered personal data.
Implications for Observability
Detailed Logging & Guardrails:
- You need fine-grained logs of every action (including external tool calls, prompt context) to detect misuse or suspicious behavior.
- Automated guardrail tooling can intercept high-risk actions, block or sanitize malicious prompts, and enforce policy rules on the fly.
Anomaly & Drift Detection:
- Observability platforms should trigger alerts on unusual user inputs indicative of prompt injection or suspicious cost spikes.
- Monitoring embedding/data drift can reveal potential poisoning attempts or domain-shift issues that could undermine compliance.
Auditability & Redaction:
- Traditional compliance standards (e.g., SOC2, HIPAA) require robust logs. Now, you must capture chain-of-thought steps and user interactions without compromising privacy.
- Systems must enable selective redaction or encryption of sensitive data to handle PII or confidential text.
- Version tracking is crucial—not just for the model, but for prompts, chain-of-thought logs, knowledge base versions, and any applied guardrails.
- Images can contain faces or unique identifiers, audio can contain personal speech patterns. Observability ideally should factor in local privacy laws and policies around image or voice data.
Real-Time Monitoring & Incident Response:
- Integrating real-time compliance checks (e.g., scanning for policy violations or hateful content) helps protect against reputational damage.
- Quick detection of harmful outputs or infinite loops in agent calls reduces the blast radius of security breaches or regulatory violations.
End-to-End Traceability:
- Observability should tie user requests to the final AI output and every intermediate step in between, enabling thorough post-incident analysis.
- This traceability is key to investigating malicious actions or proving compliance to regulators.
7. Monitoring LLM Costs
A new and sometimes surprising challenge with LLM observability is the cost of running advanced AI systems. Each invocation, especially when multi-step agents invoke multiple tool calls, can rack up additional API charges. Moreover, developer teams may not realize how quickly prompt usage grows until the monthly bill arrives.
Why This Matters
- Agent Calls Multiply Expenses: If each agent step calls an external API (like an LLM endpoint) repeatedly, costs can balloon quickly.
- Hidden or Untracked Usage: Large context windows with 10k+ tokens or repeated calls to external tools may not be fully transparent to end users of the system.
- Budget Constraints: If you’re running your own model infrastructure, GPU usage is not cheap. Even if you’re using a third-party service, tokens cost real money, and usage can spike unexpectedly.
- Observability Aspect: You need real-time metrics on token usage, number of calls, average cost per session, and historical cost trends. This can help you set alerts or throttle usage before going over budget.
Implications & Predictions
In some ways the neckbeards are right. A lot of the challenges described above (tracing agent tool calls, linked RAG DB searches, tracking token usage) are just tracing or metric generation challenges with a new twist. And arguably using AI models to detect things like hallucinations is just anomaly detection taken to another level…
…But we’re talking many levels! And just because we can draw parallels and reason about how our toolbox should change certainly doesn’t mean it’s easy, and won’t require massive re-imagining of observability platforms an AIOps. Observability 2. 0’s philosophy is definitely useful: Traditional logs/metrics/traces aren’t enough—unified, wide-structured logs are crucial. With GenAI, that data grows even wider.
Since the term AI Engineer was coined, there has been an explosion of AI applications. There is no sign of this trend reversing. More and more software systems will incorporate AI features. This means the need for adequate AI application observability will continue to grow.
Standards will definitely help here - the AI Observability Platform of the future is likely to leverage Open Telemetry (Otel) and their semantic conventions for LLM metrics.
As VCs plow all their money into AI startups, a plethora of dedicated observability for AI tools have emerged (langsmith, langfuse, arize and many others). Unless these tools are able to provide general purpose observability, then their utility will be heavily stunted for all the reasons outlined in this post. On the flipside, unless the traditional observability players (datadog, new relic, honeycomb etc.) are able to update their offerings to seriously cover the new LLM challenges, their products will also have huge gaps.
I predict:
- Multiple Tools in the short term: AI teams will often juggle specialized LLM observability solutions (langsmith, arize, etc.) alongside traditional logs/metrics.
- Unified Platforms in the long term: Vendors will race to offer cohesive solutions that track token usage, chain-of-thought, agent calls, and normal software telemetry in one place. Standards like Otel will be widely adopted.
- Security & Compliance as differentiators: Guardrails, data redaction, and step-by-step traceability will matter more than ever, especially as agentic systems cause some of the worst security incidents yet.
Looking back five years, it’s incredible how much things have advanced. But as with all rapid advancements, the tooling has lagged behind. Whoever can create a general purpose observability platform with genuine first-class support for AI will prosper - spoiler alert, my money is on Pydantic Logfire.