Scaling AI with Open-Source Models - Leveraging Together AI for Enhanced Applications
Streamlining AI Development with Open-Source Models and Robust Infrastructure
Welcome to part 7 of this AI Engineering open-source models tutorial series. Click here to view the full series.
Table of Contents
-
Introduction
-
Why Not Host the Model Ourselves?
-
Enter the AI as a Service (AIaaS) Platforms
-
TogetherAI Pros
-
TogetherAI Cons
-
Mini-Project Example with TogetherAI
-
Summary
If you’re not familiar with Large Language Model (LLM) basics (e.g. you don’t know what “inference” means), I have an Technical User’s Introduction to LLMs post that will be a better starting point.
Introduction: Inference Using Cloud Providers
So far in this AI with open-source applications series we’ve mostly looked at on-device inference. That’s because doing stuff on your own device is:
- Satisfying
- Great for learning
- Removes all privacy concerns
- Free
However, there comes a time when the following challenges can occur:
- The need for fast inference (like chatbot style) for real-time interaction. Because these cloud providers offer much higher compute power than a single local device, processing times are faster compared to even a modern laptop.
- Related to the previous point, some open-source models (like the Mixtral 8x7b) require a lot of RAM which older laptops won’t have.
- Scalability - Cloud providers can handle increasing inference demands
- Ease of development - making an API call tends to be easier than wiring up the necessary libraries and GGUF files yourself
It’s also worth noting that it’s perfectly possible to adopt a hybrid approach and use both cloud and local AI models, e.g. using an on device embedding model with a cloud model for inference.
Why Not Host Generative AI Models Ourselves?
Once we encounter a scenario where using our local device for AI model inference is no longer feasible, we have choices to make. Do we want to entirely setup and host a Large Language Model (LLM) or a Multimodal Model (MMM) for inference in the cloud ourselves? This would mean provisioning either (1) Very powerful GPU-enabled servers or (2) Setting up serverless lambdas (or equivalent) with enough GPU power to run inference. There are various challenges with this:
- Cost Management: High-performance computing resources, especially GPU-enabled servers, are expensive. Serverless options can mitigate costs but still can become expensive with scale and frequency of use.
- Complex Setup and Maintenance: Configuring, managing, and scaling cloud infrastructure requires specialized knowledge. This includes setting up virtual machines, managing network configurations, ensuring security, and updating software and models.
- Scalability: While cloud infrastructures offer scalability, predicting the scale of resources needed and efficiently scaling without incurring unnecessary costs requires careful planning and monitoring.
- Latency and Performance: Ensuring low latency and high performance for real-time or near-real-time applications can be challenging, especially when data needs to be transferred between different services or geographic locations.
- Data Privacy and Security: Hosting sensitive data or models in the cloud requires compliance with data protection regulations (e.g., GDPR, HIPAA). Ensuring data is encrypted, securely transferred, and access is controlled and logged is crucial.
- Model Management: Keeping the models up to date, version control, and managing dependencies require systematic approaches and can become complex as the project scales.
- Resource Allocation: Effectively managing GPU resources to optimize for cost and performance, especially when running multiple models or serving multiple users, requires careful allocation strategies.
- Integration Challenges: Integrating cloud-based LLM or MMM inference into existing systems or workflows might require significant architectural changes or custom development work.
All that is before we get the elephant in the room: Actually convincing a major cloud provider (AWS, Azure, GCP) to give you access to a powerful server with AI-optimised GPUs (like an NVidia A100) in small doses is hard because of the global chip shortage/craze.
This may not be such a challenge for advanced machine learning companies with significant data science & MLOps expertise, but everyone else this is a tough list to address. This is where AI as a Service Platforms come in.
Enter the AI as a Service (AIaaS) Platforms
AI as a Service Platforms do all of the model hosting work for you, and you just make API calls to do model inference. This has some parallels to Platform as a Service (PaaS) vs. Infrastructure as a Service (IaaS) in cloud computing.
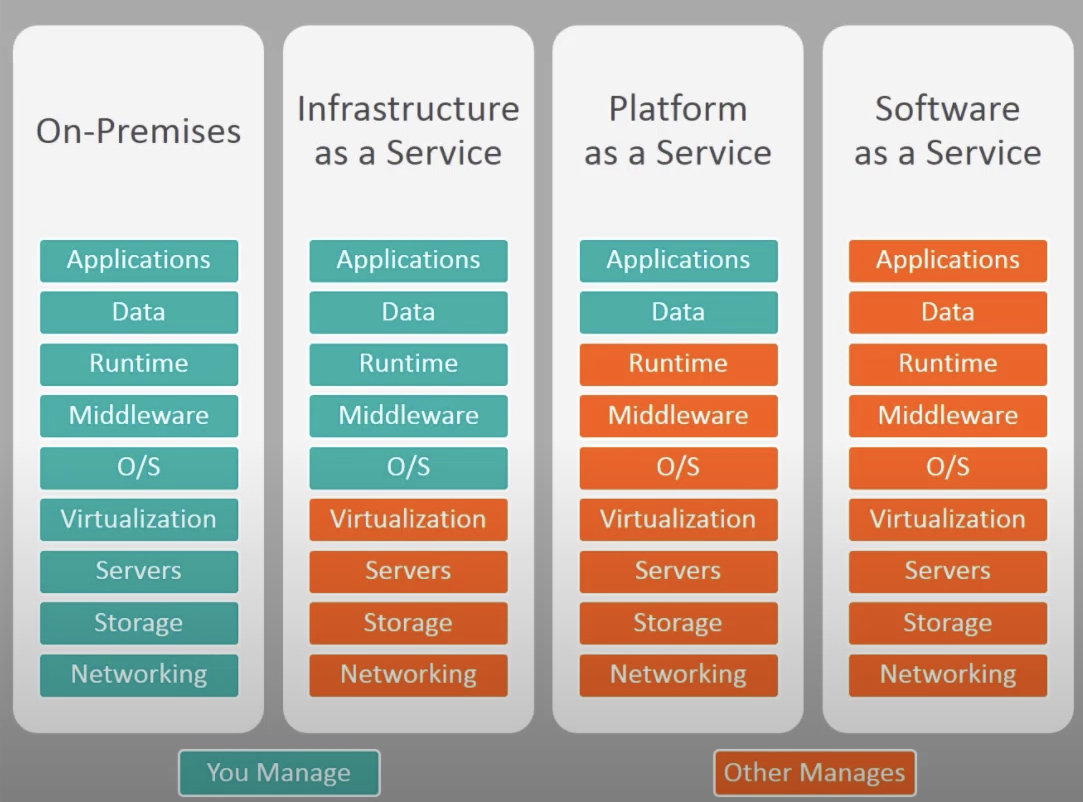
Really though, an AIaaS is most like using a metered SaaS or API product.
Unless you are working at very large scale, it’s highly likely that the AIaaS offerings will be cheaper to use than anything you could host yourself because there is an extreme price war going on at the moment driving prices down AKA “The War of the GPU Rich/Poor”.
Closed-Model Platforms
By far the most famous of these platforms is OpenAI with its ChatGPT platform. This is the OG that most people will be familiar with, and which needs little introduction. They (with GPT-4) remain top dog (although Antropic may have just caught up with Claude-3). However, there is a clear divide between the companies offering their own proprietary models as a service like OpenAI and Anthropic.
There are many downsides to only using proprietary AI solutions, namely:
- Lack of Transparency: Closed-source models do not provide access to their underlying algorithms, making it difficult for users to understand how decisions are made or outcomes are generated. This opacity can be problematic in critical applications where understanding the decision-making process is essential.
- Limited Customization: Users have restricted ability to modify or tweak the models (via fine-tuning) to better suit their specific needs or to optimize performance for particular tasks. This can result in less efficient or less effective use of the AI in niche applications.
- Dependency and Lock-in: Relying on proprietary models can lead to vendor lock-in, where users become dependent on a single provider for updates, support, and continued access to the service. This can limit flexibility and bargaining power.
- Higher Costs: Proprietary models often come with subscription fees, usage costs, or licensing restrictions, which can make them more expensive in the long run compared to open-source alternatives that might be free or offer more cost-effective licensing.
- Data Privacy: Proprietary models often require sending data to the provider’s servers for processing, raising concerns about data privacy and security. Users must trust the provider to handle their data responsibly.
For these reasons, I am focusing this entire series on open-source models. Having said that, you can always use both open and closed models.
Open-Model Platforms
Since the open-source model boom that began with the release of Llama in 2023, there are now a host of pretty respectable open-source models that can be used instead of the GPTs and Claude’s of the world: For example, Mistral’s Mixture of Experts with GPT-3.5 Turbo level functionality or on the MMM side, Stable Diffusion
A number of providers offer AIaaS for these models, notably:
And many more (email me if you think I’ve missed an important player).
These platforms have their pros and cons (I’ll probably do a post covering just those soon - subscribe to my email list for updates).
In this post, I’m going to be covering TogetherAI, which is my current favorite.

TogetherAI Pros
Free Credits
Together.ai give a very clear $25 free credit to all new accounts. Considering that the most expensive open-source model inference (such as 70B parameter model variants) are priced at $0.9/million tokens, this will allow you conduct a lot of testing unless you are working with very large datasets.
Inference Is Fast
‘nuff said.
Model Selection
They offer a good selection of open-source models: over 100 leading open-source Chat, Language, Image, Code, and Embedding models are available through the Together Inference API
OpenAI Standard
Together.ai allows you to work with the openai OpenAI Python client library, which means it works
with the OpenAI standard. This makes integrating existing applications much easier.
It also means that in future if you want to completely migrate to using chatgpt then that is relatively easy to implement and you can keep the interfaces consistent. The same benefits apply if you want to develop a hybrid system that uses chatgpt for some jobs and open-source models for other inference. For my money, this feature of “playing well with the ecosystem” is one of the major selling points of Together AI.
from openai import OpenAI
client = OpenAI(
api_key=TOGETHER_API_KEY,
base_url="https://api.together.xyz/v1"
)
def get_embeddings(texts, model="togethercomputer/m2-bert-80M-32k-retrieval"):
texts = [text.replace("\n", " ") for text in texts]
outputs = client.embeddings.create(input = texts, model=model)
return [outputs.data[i].embedding for i in range(len(texts))]
return get_embeddings(texts)
Funding & Stability
Together.ai just raised a $102M series A round, so they are unlikely to vanish anytime soon. Also, after listening to the founders (Vipul Prakash & Ce Zhang) on the latent space podcast it’s clear that they know what they’re doing. They also have a research lab, which makes them quite unusual for a GPU infrastructure company.
TogetherAI Cons
Inference Is Not Their Top Focus
As this Hacker News thread highlights, model training is the primary focus of Together AI. End-to-end model training is where they are earning more money. As a result, there is a risk that the inference side of the product becomes more of an afterthought, although I see little evidence of that right now.
Privacy Concerns
Just as when sending data to OpenAI or Anthropic, you are placing your personal or customer data in the hands of a third party. Said third party may or may not behave wisely with the data.
Fine-Tuning
There’s probably a lot more to be said about Fine-Tuning, but I haven’t done that yet on Together AI so can’t comment.
Mini-Project Example with TogetherAI
Let’s say I want to implement a basic chatbot with FastAPI and a sprinkle of HTML. No, the design isn’t going to be scalable (we’d need to go into websockets, distributed task queues and more to do that justice).
We can use TogetherAI to make this easily.
Here’s how it would work. Install a few requirements (I recommend a virtual environment):
fastapi>=0.109.2,<1.0.0
uvicorn>=0.27.1,<1.0.0
jinja2>=3.1.3,<4.0.0
openai>=1.13.3,<1.14.0
Backend endpoint
Setup our Jinja2 location and FastAPI app & router (if you’re not familiar with FastAPI, here is my ultimate tutorial
main.py
from pathlib import Path
from fastapi import FastAPI, APIRouter
from fastapi.templating import Jinja2Templates
BASE_PATH: Path = Path(__file__).resolve().parent
TEMPLATES: Jinja2Templates = Jinja2Templates(directory=str(BASE_PATH / "templates"))
app: FastAPI = FastAPI(title="TogetherAI Inference App")
api_router: APIRouter = APIRouter()
Next we’ll create a basic endpoint to serve some HTML:
from fastapi import Request
@api_router.get("/", status_code=200)
async def ui(request: Request):
"""
Serves a UI page from the 'templates' directory.
Args:
request (Request): The request object.
Returns:
Any: A template response rendering the UI.
"""
return TEMPLATES.TemplateResponse("index.html", {"request": request})
app.include_router(api_router)
if __name__ == "__main__":
# Use this for debugging purposes only
import uvicorn
uvicorn.run(
"app.main:app", host="0.0.0.0", port=8001, log_level="debug", reload=True
)
Great, now we need some HTML in a jinja2 template, which is what the FastAPI docs recommend for templating. I’ll style the page with tailwind CSS:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Chat Interface</title>
<!-- Include Tailwind CSS -->
<link href="https://cdn.jsdelivr.net/npm/[email protected]/dist/tailwind.min.css" rel="stylesheet">
</head>
<body class="bg-gray-900 text-gray-100 flex flex-col min-h-screen justify-between">
<header class="text-center py-10">
<h1 class="text-5xl font-semibold mb-2 text-blue-400">Generic Chatbot</h1>
<p class="text-xl text-blue-200">Batch vs. Stream...</p>
</header>
<main class="mb-10">
<section class="mb-10">
<div class="max-w-2xl mx-auto px-4">
<h2 class="text-3xl font-bold mb-6 text-blue-300">Batch Chat</h2>
<form id="batchForm" class="mb-6">
<input type="text" name="user_message" placeholder="Your message here" value="Tell me about Rome"
class="w-full p-3 rounded bg-gray-700 mb-4 focus:ring-blue-500 focus:border-blue-500">
<input type="number" name="max_tokens" placeholder="Max tokens" value="50"
class="w-full p-3 rounded bg-gray-700 mb-4 focus:ring-blue-500 focus:border-blue-500">
<button type="submit" class="w-full bg-blue-600 hover:bg-blue-700 text-white font-bold py-3 px-6 rounded transition duration-200">
Send
</button>
</form>
<p class="text-lg bg-gray-800 p-3 rounded">Batch Response: <span id="batchResponse" class="text-green-400"></span></p>
</div>
</section>
</main>
</body>
</html>
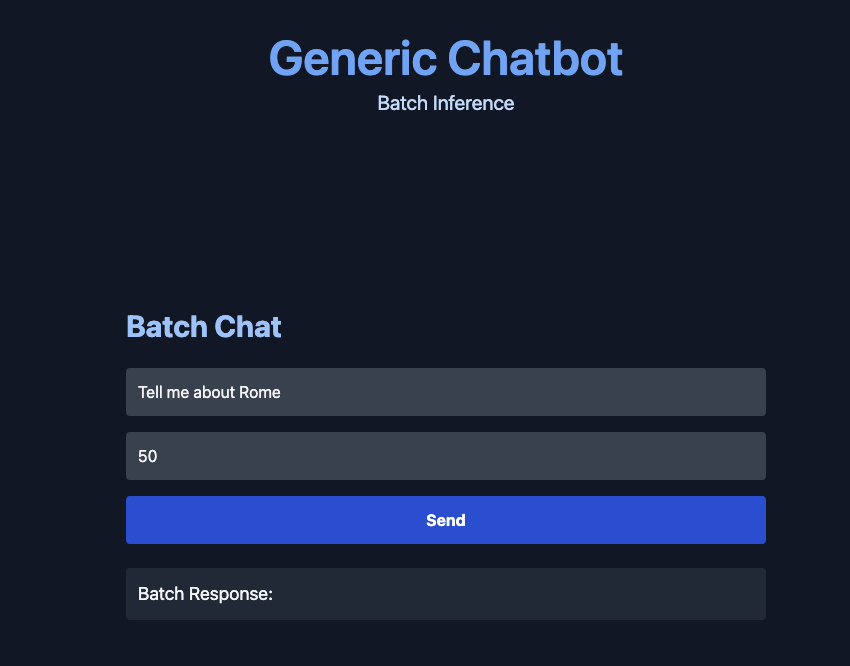
Great, now when we run our FastAPI we see:
Now it’s time to add the LLM functionality with TogetherAI. We’ll setup the client to make calls to the Together API using FastAPI’s dependency injection framework:
deps.py
from typing import AsyncGenerator
from openai import AsyncOpenAI
async def get_llm_client() -> AsyncGenerator[AsyncOpenAI, None]:
"""
Asynchronously generates and provides an AsyncOpenAI client configured with API key and base URL from settings.
This asynchronous generator function initializes an AsyncOpenAI client using configuration details specified in the
application settings, particularly leveraging the Large Language Model (LLM) settings for the API key and the base URL.
It then yields this client.
Yields:
AsyncOpenAI: An instance of AsyncOpenAI client configured for interacting with the API asynchronously.
"""
client = AsyncOpenAI(
api_key=os.environ.get(TOGETHER_API_KEY),
base_url="https://api.together.xyz"
)
yield client
Here we’re using the async version of the OpenAI class from openai.
Note that this illustrates one of the nice things about working
with the Together Platform - because they are compatible with the
openai client standard, then swapping out calls to use GPT-4 if we
need better performance is trivial.
We will inject the LLM client into a new endpoint, which is where we will generate the chatbot responses:
main.py (continued)
from openai import AsyncOpenAI
from fastapi import Depends
import deps # update path as per your project setup
@api_router.post("/inference/batch/", status_code=200)
async def run_chat_inference(
chat_input: str,
llm_client: AsyncOpenAI | None = Depends(deps.get_llm_client),
):
"""
Executes a batch inference using the provided chat input and returns the AI model's response.
Args:
chat_input str: The chat input containing the user's message.
llm_client (AsyncOpenAI | None): The asynchronous OpenAI client, obtained via dependency injection.
Returns:
Any: The cleaned and formatted response from the AI model.
"""
chat_completion = await llm_client.chat.completions.create(
messages=[
{"role": "system", "content": "You are an AI assistant"},
{"role": "user", "content": chat_input},
],
model="mistralai/Mixtral-8x7B-Instruct-v0.1",
max_tokens=100,
temperature=0.8,
)
return chat_completion.choices[0].message.content.strip()
Now we can pass a batch response to our client.
All that remains is to add a little bit of vanilla JavaScript to our template to call this endpoint. Naturally, you could also implement this using ReactJS as I demonstrate here
index.html
<script>
async function handleSubmit(e) {
e.preventDefault();
const form = e.target;
const formData = new FormData(form);
const userMessage = formData.get('user_message');
const endpoint = '/inference/batch/';
const responseContainerId = 'batchResponse';
// Clear previous response when "Send" is clicked again
document.getElementById(responseContainerId).innerText = '';
try {
const response = await fetch(endpoint, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ user_message: userMessage }),
});
const data = await response.text();
document.getElementById(responseContainerId).innerText = data;
} catch (err) {
console.error('Fetch error:', err);
}
}
document.getElementById('batchForm').addEventListener('submit', handleSubmit);
</script>
Now we can reload our server (you can automate this with a flag), open the home page and click the “Send” button and get our batch inference response back!
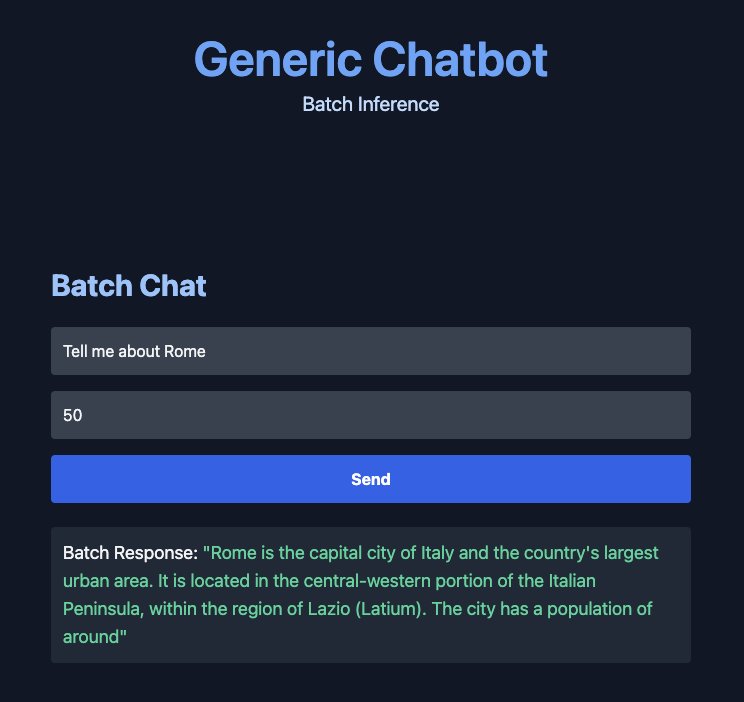
For more advanced versions of the above code, including streaming, Retrieval Augmented Generation (RAG) and productionization, check out my Building AI Applications with Open-Source Course
Summary
As you can see from the very simple project above, by using the TogetherAI API, we are able to build an AI-powered application that uses open-source models very quickly.
Right now the default for many organizations is default OpenAI & GPT-4. But as open-source models become more high quality, and compete on pricing, I expect more organizations to consider open-source use cases. When that time comes, Together AI is a solid choice.