The Technical User's Introduction to LLM Tokenization
Exploring the Mechanics of Tokenization in Large Language Models
This blog post is basically my notes from Andrej Karpathy’s excellent YouTube talk Let’s build the GPT Tokenizer
Table of Contents
-
Introduction
-
Why Does Tokenization Matter?
-
Tokenization Details
-
Naive Vocabulary Construction Example: Shakespeare
-
Understanding Tokenization Challenges
-
Interlude - Why Can’t we Just Use the Unicode Codes Points?
-
Byte Pair Encoding (BPE) Algorithm
-
What’s the Difference Between Tokenization and Embeddings?
If you’re not familiar with Large Language Model (LLM) basics, I have an Technical User’s Introduction to LLMs post that will be a better starting point.
Introduction: What Is Tokenization?
“Tokens” are talked about a lot in AI research, e.g. in the Llama 2 paper, the authors mention that they trained on 2 trillion tokens of data.
Tokens are the fundemantal unit, the “atom” of Large Language Models (LLMs). Tokenization is the process of translating strings (i.e. text) and converting them into sequences of tokens and vice versa.
In the machine learning context, a token is typically not a word. It could be a smaller unit, like a character or a part of a word, or a larger one like a whole phrase. The size of the tokens vary from one tokenization approach to another, as we will see in this post.
Unsurprisingly, tokenization is performed by a component called a “Tokenizer”. This is a separate, independent module from the Large Language Model. It has its own training dataset of text, and that may be completely different to the LLM training data.
An example of an open source tokenizer is tiktoken from OpenAI.
Why Does Tokenization Matter?
Tokenization is responsible for much LLM “weirdness”. Many issues that you might think are to do with the neural network architecture, or the LLM itself are actually issues related to tokenization. Here is a non-exhaustive list of issues that can be traced back to tokenization:
- LLM can’t spell words
- Simple string processing tasks (like reversing a string)
- Worse performance for non-English languages (e.g. Japanese)
- Poor performance at simple arithmetic
- Why GPT-2 had trouble with coding Python
- Trailing whitespace
- Why the (earlier versions) of GPT went crazy if you asked it about “SolidGoldMagikarp”
- Why you should use YAML over JSON for structured data
We’ll see more about why tokenization causes these issues in this post.
Tokenization Details
Here are the steps involved in tokenization. Some of these won’t make sense yet, we will discuss them further throughout this post
Pre-Training Phase: Establishing the Vocabulary
- Collect Training Data: Gather a large corpus of text data that the model will learn from.
- Initial Tokenization: Apply preliminary tokenization methods to split the text into basic units (words, subwords, or characters).
- Vocabulary Creation: Choose a tokenization algorithm (e.g., Byte Pair Encoding (BPE), WordPiece, SentencePiece) to generate a manageable and efficient set of tokens.
- Apply Algorithm: Run the selected algorithm on the initial tokens to create a set of subword tokens or characters that capture the linguistic nuances of the training data.
- Assign IDs: Each unique token in the resulting vocabulary is assigned a specific integer ID.
Real-Time Tokenization Process
- Convert incoming text into the tokens found in the established vocabulary, ensuring all text can be represented.
- Map each token to its corresponding integer ID as defined in the pre-established vocabulary.
- Add any necessary special tokens to the sequence for model processing requirements.
Naive Vocabulary Construction Example - Shakespeare’s Works
Let’s use Shakespeare’s works as an example to illustrate a basic approach to vocabulary creation for tokenization, and then contrast it with more advanced methods used in state-of-the-art models.
Basic Character-Level Tokenization:
- Mapping Characters to Integers: Initially, every unique character in Shakespeare’s texts (letters, punctuation) is assigned a unique integer. For simplicity, let’s say Shakespeare’s texts contain 26 lowercase letters (a-z), 26 uppercase letters (A-Z), and 13 symbols (including spaces and common punctuation), totaling 65 unique characters.
- Creating a Lookup Table: A table is created with 65 entries, each corresponding to one of these unique characters. This table serves as a vocabulary, where each row represents a different character.
- Token-to-Vector Conversion: When tokenizing text, each character is identified by its assigned integer, which is used to retrieve a specific row from the table. This row contains a vector of trainable parameters that represent the character in a format the model can process. Training and Transformation: These vectors are then used in the model’s training process, where they are adjusted during backpropagation to better capture the relationships between characters. In the context of a transformer model, these vectors are what feed into the network, allowing it to “understand” and generate text based on the input tokens.
Beyond Character-Level: State-of-the-art models typically go beyond simple character-to-integer mappings. Instead of treating each character as a separate token, these models use more sophisticated methods to tokenize text into larger chunks, or “subwords.” We’ll look at a demo of this now.
Understanding Tokenization Challenges - Demo
This tiktoken web app shows you tokenization in the browser:
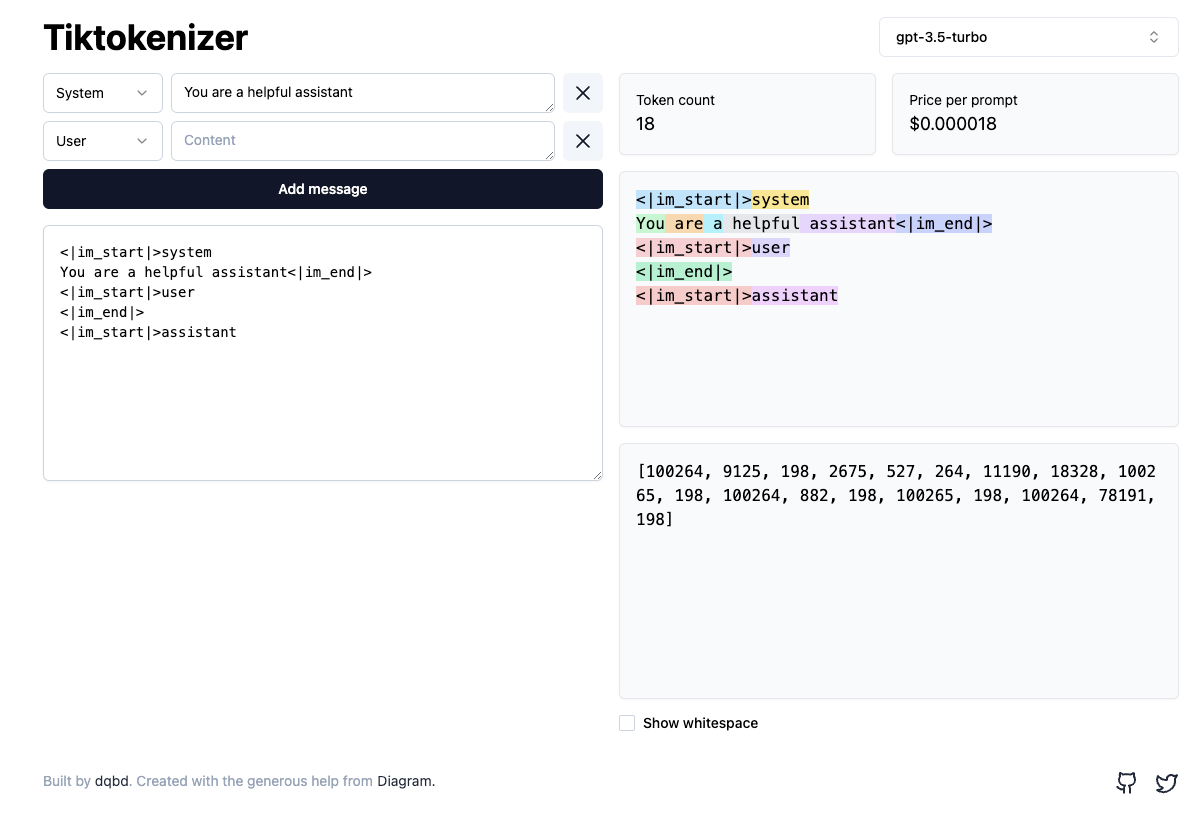
Try typing some sentences, and watch the tokens get generated (and the token count and price per prompt increase).
As another exercise, select the GPT-2 encoder from the dropdown:
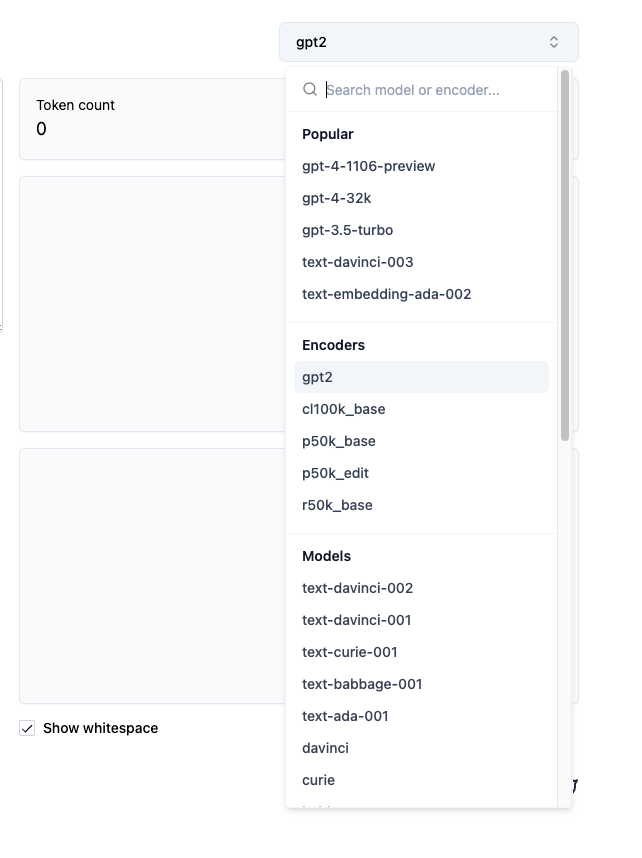
When you hover over the text on the right hand side (after checking the “Show whitespace” checkbox), you’ll see the tokens highlighted. Notice they are “chunks” that often include the space character at the start:
chunks:
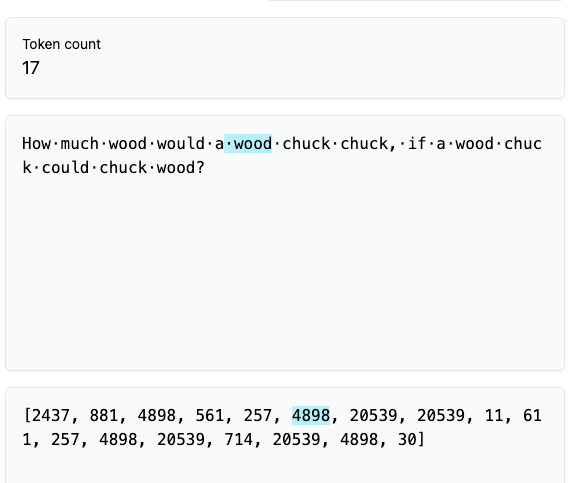
Here’s another example:
Python
The language python.
PYTHON
python

Notice how the token chunks and numeric representations are different depending on:
- Whether there is a space before the word
- Whether there is punctuation
- Depending on the letter case
The LLM has to learn from raw data that despite the fact that these words have different tokens, they are the same concept (or at least extremely similar). This reduces performance.
Other Human Languages
If you compare the chunk size for English with other languages, you’ll tend to see that the number of tokens used for other languages is much larger. That’s because the “chunks” for other languages are a lot more broken up. This bloats the sequence length of all the documents.
In the attention of the machine learning transformer, you are more likely to run out of context because even though you may be saying the same thing, you have consumed more tokens because your chunks are smaller. This has to do with the training set used for the tokenizer and the tokenzier itself.
Ultimately, this wasteful context window utilization for non-English languages results in poorer performance by the LLM for non-English queries.
Tokenization and Code - Python
In the case of Python, for OpenAI’s GPT-2 encoder it wasted a lot of tokens on individual whitespace characters used in the indentation of bits of Python code. Similar to non-English languages, this results in a lot of bloat of the LLM’s limited context window and drop in performance.
Config: YAML vs. JSON
It turns out that YAML is more “dense” than JSON and uses fewer tokens to do the same thing.
Here’s a simple example:
loggingLevel: DEBUG
database:
host: localhost
port: 5432
user: admin
password: secret
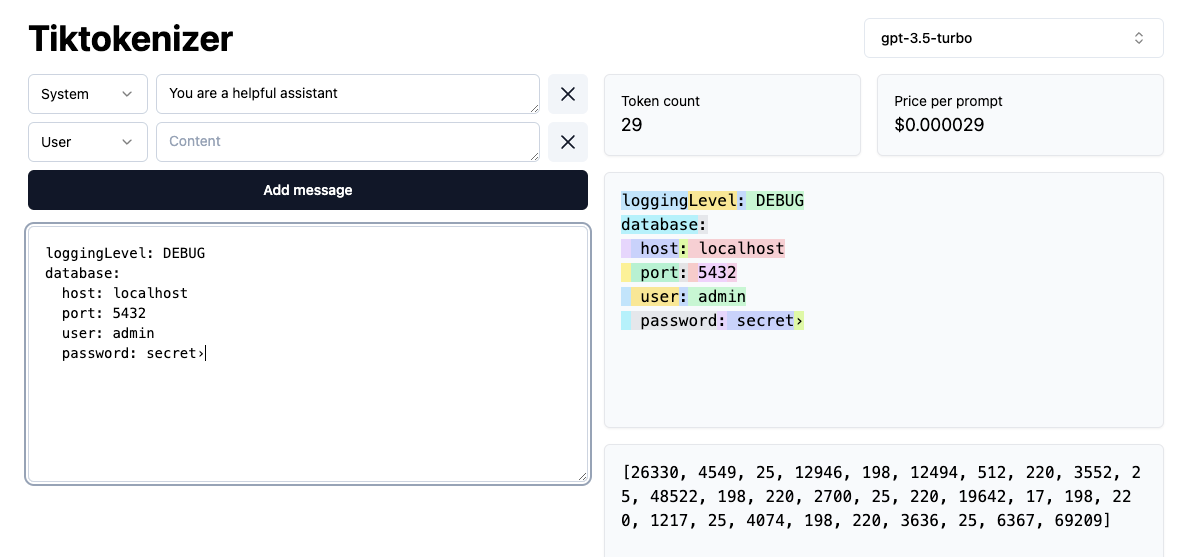
YAML: 29 tokens
{
"loggingLevel": "DEBUG",
"database": {
"host": "localhost",
"port": 5432,
"user": "admin",
"password": "secret"
}
}
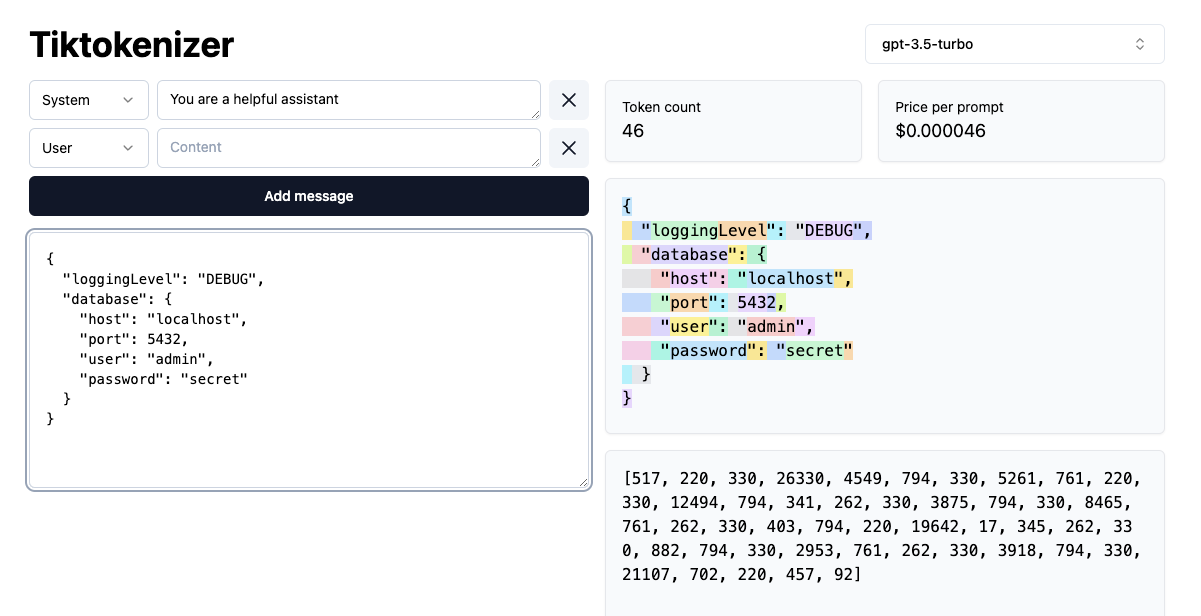
JSON: 46 tokens
This increased bloat for JSON means that:
- The LLM will find it harder to understand (less dense, more likely to not fit in context window)
- It will cost you more money (you effectively pay per token when making API calls to OpenAI)
Contrasting Tokenizers
This tokenizer inefficiency can be observed when constrasting tokenizers. Let’s take a Python FizzBuzz script:
def fizz():
for i in range(1, 101):
if i % 5 == 0 and i % 3 == 0:
print("fizzbuzz")
elif i % 5 == 0:
print("buzz")
elif i % 3 == 0:
print("fizz")
else:
print(i)
We observe it in the tiktokenizer tool with the GPT-2 encoder set:
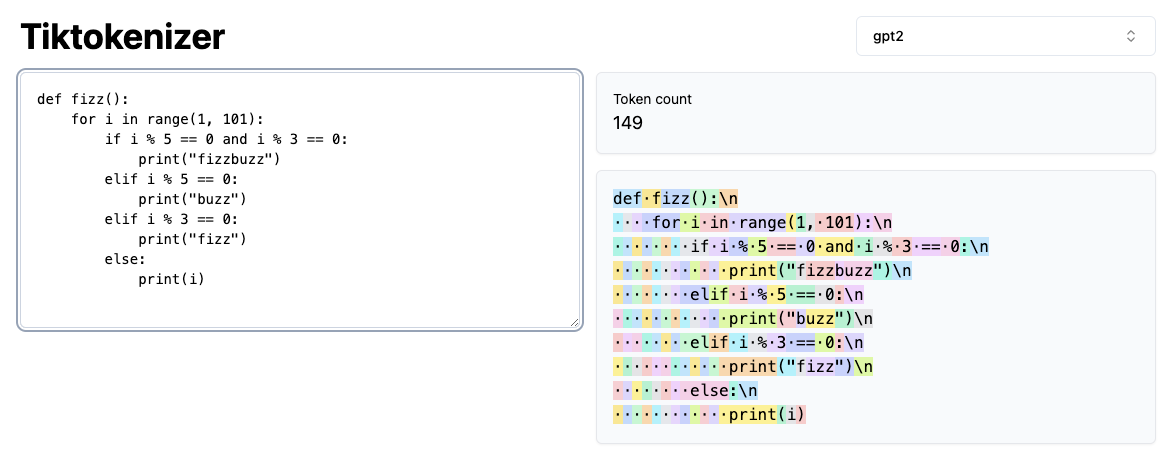
Note it generates a token count of 149.
Now if we select the cl100k_base (which is the tokenizer for GPT-4), and notice that for the exact same string the token count drops significantly to 77.
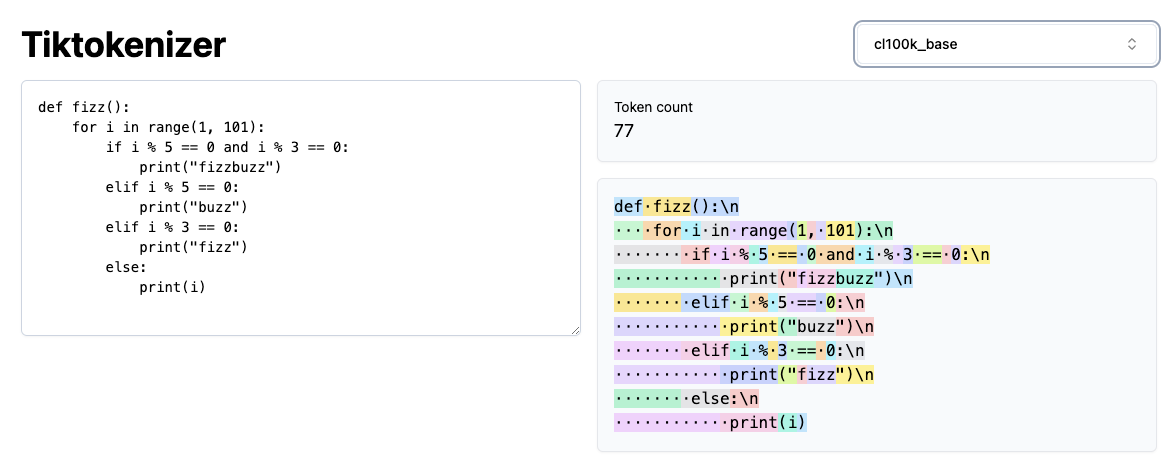
This means that our input to the LLM transformer is much denser. As a result the context window will contain roughly twice as much information as we try to do text generation. The model will be much better able to predict the next token (which is what fundamentally drives quality in generative AI).
The reason why cl100k has better performance than the GPT-2 chatgpt encoder is that it has roughly twice the number of tokens. However, there is a class nlp trade-off here. Just increasing the number of tokens incurs a penalty - as you increase the number of tokens, your embedding table grows larger. Also, at the output when trying to predict the next token, there is softmax, and that grows as well.
There is a sweet spot for this tradeoff, which GPT-4 was much closer to that GPT-2.
Interlude: Why Can’t we Just Use the Unicode Codes Points?
In Python, string characters have a Unicode text encoding. If we run:
unicode_points = [ord(char) for char in "hello world!"]
print(unicode_points)
We can see the encoding for each character in the string:
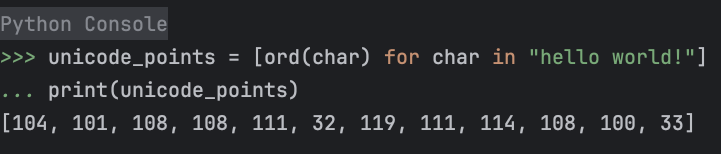
What is wrong with just using this encoding?
- The vocabulary would be quite long at 150k - far from the “sweet spot” we discussed in the previous section
- The unicode standard keeps changing - so it’s not a stable representation over time
Encodings
The Unicode consortium defines 3 types of encodings you have probably come across before:
- UTF-8
- UTF-16
- UTF-32
These encodings take unicode text and translate it into binary data for transmission via byte streams. For a detailed explanation of unicode see this post.
We wouldn’t want to naively use the UTF-8 encoding because all our text would be stretched out over very long sequences of bytes. This is inefficient. In order to remedy this, we turn to the byte-pair encoding algorithm.
Byte Pair Encoding (BPE) Algorithm
The paper that introduced byte pair encoding (aka digram coding) as a method for tokenization in the context of LLMs was:
“Language Models are Unsupervised Multitask Learners” (Radford et al., 2018)
In this paper, the vocabulary is expanded to 50,257 tokens, and a context size of 1024 tokens.
The algorithm is not too complicated:
- Given an input sequence
- Iteratively find pair of tokens that occurs most frequently
- Replace that pair with a single new token, which is appended to our vocabulary
- Repeat
For a complete overview, the wikipedia entry for BPE is excellent.
In this way, the algorithm compresses the length of the sequence, with the trade-off being it has a larger vocabulary of tokens. There is a sweet spot for this trade-off, and at the time of writing the state-of-the-art shows it to be a vocabulary length of around 100k tokens. This is a good post about the details of the trade-off.
BPE has some desirable properties:
- It’s reversible and lossless, so you can convert tokens back into the original text
- It works on arbitrary text, even text that is not in the tokeniser’s training dataset
- It compresses the text: the token sequence is shorter than the bytes corresponding to the original text. On average, in practice, each token corresponds to about 4 bytes.
- It attempts to let the model see common subwords. For instance, “ing” is a common subword in English, so BPE encodings will often split “encoding” into tokens like “encod” and “ing” (instead of e.g. “enc” and “oding”). Because the model will then see the “ing” token again and again in different contexts, it helps models generalise and better understand grammar.
As we saw in this post using local open-source LLMs with llama-cpp when you run local inference you will see details about the model logged. Here is a snippet from loading the mistral-7b-instruct-v0.2 model:
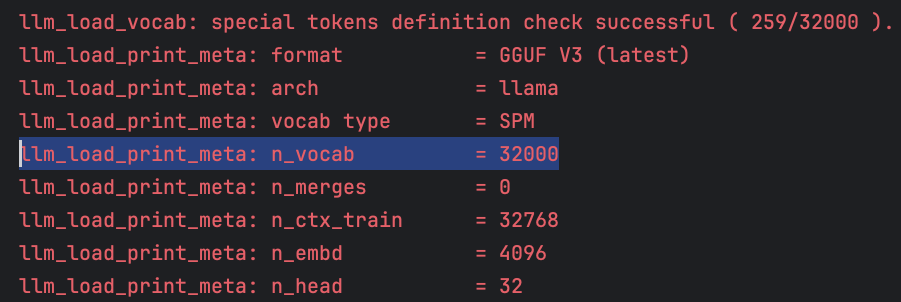
Notice the n_vocab line, showing us that this LLM’s tokenizer has a vocab size of 32k tokens.
This process is how one trains a tokenizer component: translating back and forth between raw text and sequences of tokens. This is typically a separate pre-processing step when creating the overall LLM. Translating from raw text to tokens is called encoding. Translating back from tokens to text is called decoding.
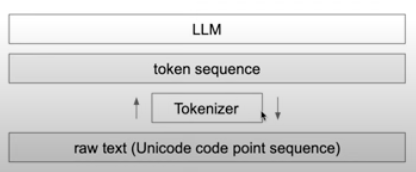
The LLM (which recall is separate from the Tokenizer), only ever sees the tokens, never any text.
Special Tokens
If you look at model prompt instructions on huggingface, you’ll see some examples of their special characters. These are used for things like delimiting the end of a user prompt.
Here’s an example: <|endoftext|>
If we look at its token, you can see it is a single token:
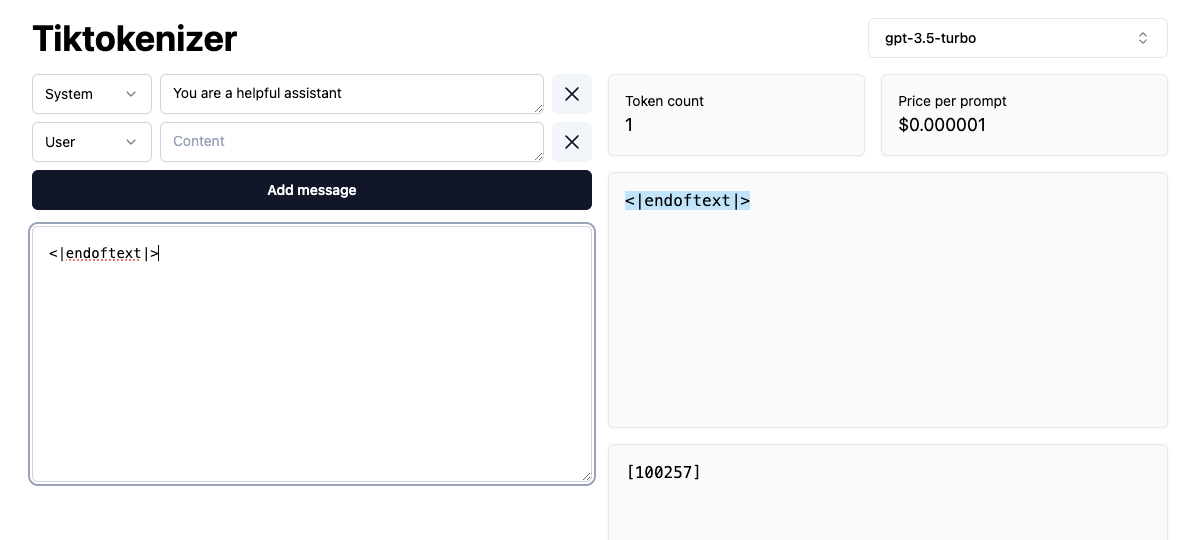
This is very important during the fine-tuning stage of LLM development (see this intro for details), because we need to be able to delimit conversations and keep track of the flow of a conversation. Fine-tuning is where the LLM develops more “assistant-like” behavior, and so the need to understand conversation flows (and questions and answers) is paramount.
What’s the Difference Between Tokenization and Embeddings?
LLM tokenization and embeddings are two distinct but complementary processes involved in how Large Language Models (LLMs) like GPT understand and generate text. Here’s a concise breakdown of each and how they differ:
LLM Tokenization
- Purpose: Tokenization is the process of converting raw text into a series of tokens. These tokens can be words, subwords, or characters, depending on the tokenization strategy.
- Process: It involves breaking down the text into manageable pieces that the model can interpret. This might involve splitting text based on spaces and punctuation, then further breaking down words into subwords or characters if they’re not in the model’s predefined vocabulary.
- Outcome: The result is a sequence of tokens that represents the original text in a form that the model can process. Each token is mapped to a unique integer ID based on the model’s vocabulary.
Embeddings
- Purpose: Embeddings are dense, low-dimensional, continuous vector representations of tokens. They capture semantic and syntactic meanings of tokens, enabling the model to understand the nuances of language.
- Process: Once the text is tokenized, each token (represented by its integer ID) is mapped to an embedding vector. These vectors are learned during the model’s training process and are stored in an embedding matrix or table.
- Outcome: The embeddings serve as the input to the neural network layers of the LLM. They allow the model to perform computations on the tokens, capturing relationships and patterns in the dataset.
Key Differences
- Stage in Processing Pipeline: Tokenization is a preprocessing step, converting text into a form that the model can understand (tokens). Embeddings come after tokenization, transforming tokens into rich vector representations.
- Role: Tokenization is about structurally breaking down and representing text, while embeddings are about capturing and utilizing the semantic and syntactic meanings of tokens.
- Representation: Tokenization results in discrete, integer representations of text elements. Embeddings convert these integers into continuous vectors that encode linguistic information.
In summary, tokenization and embeddings are two essential steps in the data processing pipeline of LLMs, each serving a distinct purpose. Tokenization translates raw text into a discrete sequence of tokens, and embeddings transform these tokens into meaningful vector representations that feed into the neural network for further processing.
Phew! That was a heavy one. If you want to go deeper into tokenization, Andrej Karpathy has also created a repo with code and exercises here.
Ready to try using open-source LLMs on your laptop? Check out the tutorial series…