First Impressions of Data Science Version Control (DVC)
Machine Learning System Tooling
Introduction
I was recently approached by the team developing Data Science Version Control (DVC). What follows are my initial thoughts after giving the system a test for a day.
Contents
Machine Learning System Challenges and DVC
Once machine learning models leave the research environment, and particularly when they need to be regularly updated in production, a host of challenges start to become apparent. The technical debt of ML systems has been best documented by Sculley et al. Chief among these challenges is the need for reproducibility, i.e. can you recreate a prediction you have made in the past? Here’s a talk Soledad Galli and I gave on this topic - paramount among reproducibility concerns are the following:
- Effectively versioning your models
- Capturing the exact steps in your data munging and feature engineering pipelines
- Dependency management (including of your data and infrastructure)
- Configuration tracking
The thing is, there is a lot involved in the above steps. No one tool can do it all for you. In 2019, we tend to find organizations using a mix of git, Makefiles, ad hoc scripts and reference files to try and achieve reproducibility. DVC enters this mix offering a cleaner solution, specifically targeting Data Science challenges. The DVC docs state that:
One of the biggest challenges in reusing, and hence the managing of ML projects, is its reproducibility […] DVC has been built to address the reproducibility.
In terms of core features, DVC is centered around:
- Version control for large files
- Lightweight pipelines with reproducibility built in
- Versioning and experimentation management on top of git
In order to test these capabilities, I decided to introduce DVC into one of my ML projects.
A Typical Approach
I chose to update the example project from the Train In Data course: Deployment of Machine Learning Models. This project has a reasonably realistic setup for a production machine learning model deployment, complete with CI/CD pipeline integration and model versioning. The model in question is a Convolutional Neural Network for image classification, which uses data from the Kaggle v2 Plant Seedlings Dataset. The training data is 2GB and is not kept under version control. Prior to using DVC, the way this system aimed for reproducibility was:
- Every time a feature branch is merged into master, a new version of the model is trained and published to a package index (Gemfury) in CI.
- Data preparation and feature engineering steps underpinning the training are captured through a scikit-learn pipeline.
- This package can only ever contain one version of the model to prevent confusion. Attempting to upload the same version of the model will cause the upload to fail (i.e. if the engineer forgets to increment the VERSION file).
- A reference url to the training dataset is stored in a .txt file which is published as part of the package. In the project, this is simply the kaggle url, but for a real system you would use something like an AWS S3 bucket.
DVC Setup
DVC is designed to be agnostic of frameworks and languages, and is designed to run on top of Git repositories.
If you wish to follow along, go ahead and clone the modified project. The first step is to install DVC. Thankfully, this turned out to be simple with pip:
pip install dvc
For those not using Python, there are also binary packages on the DVC install page.
The next step was to initialize the DVC project, which is very similar to setting up git with:
dvc init (note that this command has already been run in the test repo).
Once this command is run, a .dvc folder is created, where DVC tracks changes to the files you instruct it to monitor (more on this in the next section).
DVC expects you to define a data remote, which is the central location where data/model files will be stored. You can choose from:
- Local
- AWS S3
- Google Cloud Storage
- Azure Blog Storage
- SSH
- HDFS
- HTTP
I opted for AWS S3, which meant that I had to install an extra dependency:
pip install dvc[s3]
This installs the aws-cli and Boto3. The docs do not mention this, but you will then also need to run aws-cli configure and add your appropriate AWS keys (don’t neglect to use a restricted key via AWS Identity and Access Management) with access to an S3 bucket, where your project data and model versions will be stored. Once this is done, the final setup step is to set the remote with:
dvc remote add -d myremote s3://YOUR_BUCKET_NAME/data
Tracking Data with DVC
Once setup was complete, I was ready to add the most problematic of my project’s data dependencies to DVC - namely, the 2GB of training images from Kaggle.
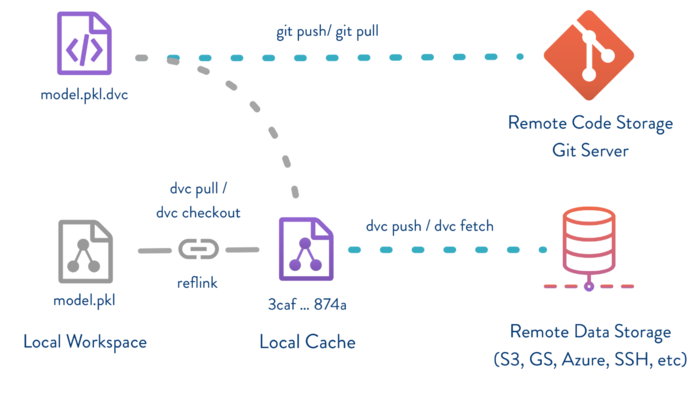
DVC streamlines large data files and binary models into a single Git environment and this approach will not require storing binary files in your Git repository.
To fetch the files from Kaggle you can just login to Kaggle and download the zipfile via the UI, in the original repo this was done in CI via the kaggle-cli. I unzipped the training data into this directory:
packages/neural_network_model/neural_network_model/datasets/
Then I was ready to use the dvc add command to begin tracking the training data with DVC:
This command [dvc add] should be used instead of git add on files or directories that are too large to be put into Git. Usually, input datasets, models, some intermediate results, etc. It tells Git to ignore the directory and puts it into the DVC cache (of course, it keeps a link to it in the working tree, so you can continue working with it the same way as before). Instead, it creates a simple human-readable meta-file that can be considered as a pointer to the cache.
My training data fits this description well, so I entered: dvc add packages/neural_network_model/neural_network_model/datasets/
Here is the output from my terminal:
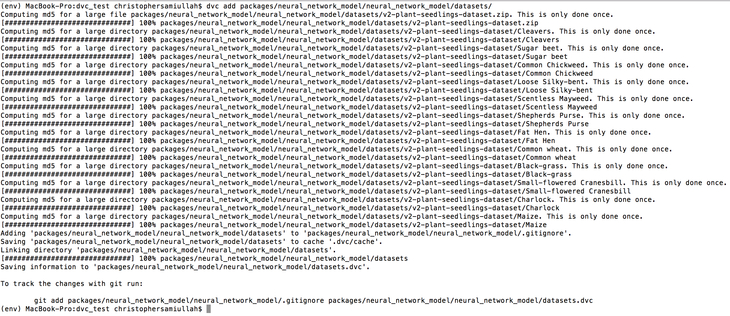
Once this was done, I could see the datasets.dvc appear. This is where DVC tracks file changes through MD5 hashes. For more details on how this works, see the DVC documentation. I proceeded to commit these .dvc files to Git version control. I then pushed the data files to the DVC remote by running
dvc push (this took a few minutes). This command uploaded the files to my S3 bucket. To test my new dataset tracking, I deleted the images with:
rm -rf v2-plant-seedlings-dataset and then ran
dvc pull
Lo and behold, the files were restored immediately (much faster than my kaggle fetch script). At this point I started feeling like DVC was something pretty useful. I went into my circle CI config.yml file and replaced all the Kaggle fetching scripts with dvc pull
This is the “basic” collaboration workflow of DVC:
DVC remotes, dvc push, and dvc pull provide a basic collaboration workflow, the same way as Git remotes, git push and git pull
Next I moved on to the more advanced features.
DVC Pipelines
Pipelines are where DVC really starts to distinguish itself from other version control tools that can handle large data files. DVC pipelines are effectively version controlled steps in a typical machine learning workflow (e.g. data loading, cleaning, feature engineering, training etc.), with expected dependencies and outputs. Under the hood, DVC is building up a Directed Acyclic Graph (DAG) which is a fancy way of saying a series of steps which can only be executed in one direction:
DVC scans the DVC files to build up a Directed Acyclic Graph (DAG) of the commands required to reproduce the output(s) of the pipeline. Each stage is like a mini-Makefile in that DVC executes the command only if the dependencies have changed.
For my image classification model, I was already using a scikit-learn pipeline to manage my data preparation, feature engineering and model training. But I still could wrap the training command as a single DVC pipeline step, so I went ahead and did that with the DVC run command (Note that I had to update my PYTHONPATH with the child neural_network_model directory to get this to work):
dvc run -f train.dvc -d packages/neural_network_model/neural_network_model/train_pipeline.py \
-d packages/neural_network_model/neural_network_model/datasets \
-o packages/neural_network_model/neural_network_model/trained_models/cnn_model.h5 \
-o packages/neural_network_model/neural_network_model/trained_models/cnn_pipe.pkl \
-o packages/neural_network_model/neural_network_model/trained_models/classes.pkl \
-o packages/neural_network_model/neural_network_model/trained_models/encoder.pkl \
python packages/neural_network_model/neural_network_model/train_pipeline.py
There’s a lot happening in the above command, so here is a breakdown:
- I define a pipeline step “train” via
run -f train.dvc - The pipeline’s dependencies with
-di.e. the 2GB of images in /datasets - The pipeline’s four expected output files (each specified with
-o). You can also specify a single output directory rather than each individual file. - The script to start the training step, namely
train_pipeline.py
Once this ran, the last step was to push this newly defined pipeline with: dvc push
With my pipeline defined, a series of ascii visualization commands opened up to me:
dvc pipeline show --ascii train.dvc
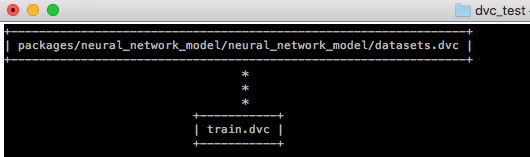
dvc pipeline show --ascii train.dvc --commands

And a command to view the four output files:
dvc pipeline show --ascii train.dvc --outs
This run command, therefore, has all the functionality of the add command we looked at in the previous section, but also includes dependency and output tracking. At this point I was getting very interested in DVC. Next I delved into reproducibility…
Reproducibility
The DVC docs say:
Reproducibility is the time you are getting benefits out of DVC instead of spending time defining the ML pipelines […] The most exciting part of DVC is reproducibility.
I am inclined to agree. The DVC reproducibility feature ties together all the steps we have looked at so far. Now, instead of calling my train_pipeline.py script, I call: dvc repro train.dvc, referencing the pipeline setup in the previous section.
If no changes are detected, the expected output files from this step will be pulled from remote storage. If changes are detected in any of the dependencies (e.g. a change in the train_pipeline.py script, or a change in the data), then DVC will warn you and rerun the step. It will also warn you if your output files are missing and being fetched from the DVC remote, for example after deleting the cnn_model.h5 output file and running dvc repro train.dvc I got:
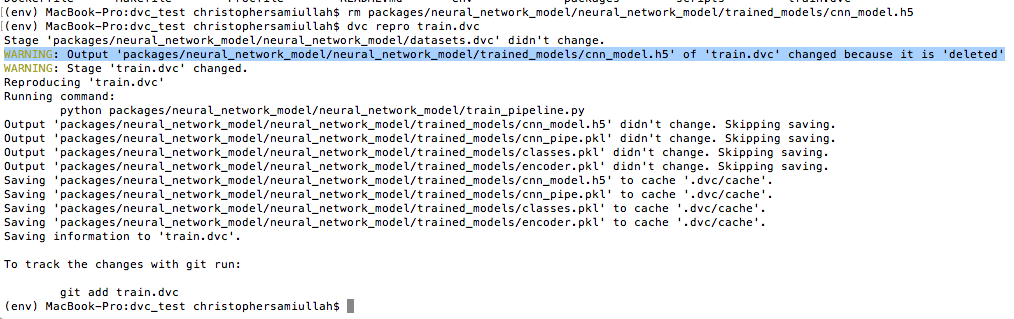
When I saw this, I really started to appreciate the power of DVC.
Versioning
One of the things that took me a bit of time to grasp was how to version models with DVC. In hindsight, it’s simple: you basically just use Git. For example:
- If I commit a change and tag a v1.0 model:
git tag -a "v1.0" -m "model v1.0, including Sugar beet" - Then make a change to my data, e.g.
cd into the datasets directory and remove Sugar beet
rm -rf Sugar\ beet/ - Then update DVC with the new data.
dvc add datasets - And tag the new 2.0 model version:
git add --allgit commit -m "update datasets dvc"git tag -a "v2.0" -m "model v2.0, no Sugar Beet in training data"
Then if I want to go back to the old v1.0 model I run two checkout commands:
git checkout v1.0
then
dvc checkout
Now I’ve restored my repo to its v1.0 state.
Improvements in my current workflow
To complete the addition of DVC to my project, I performed the following adjustments to my circleci config (pr details here):
- Installed dvc and added the AWS credentials
- Replaced my Kaggle fetch script with
dvc pull - Instead of running the
train_pipeline.pyscript directly, I ran:dvc repro train.dvc - Given more time, I can see how I would replace my VERSION files to use git tags, since I now have the ability to link a tagged release with my model outputs and input data via .dvc files.
- Given more time, I would also now be able to remove the test dataset (tracking it with DVC instead) from my published package, which would be welcome.
The repro step, in particular, is valuable because it ensures that the model I publish includes any changes to any dependencies. In theory (and I’ll discuss this in the risks section), this is an excellent safeguard.
Evaluation
How Does DVC Compare to Alternatives?
This article gives an excellent overview of the strengths and weaknesses of git-lfs and git-annex. DVC seems to trump git-lfs in the following key ways:
- git-lfs is bound to a single upstream, e.g. github/bitbucket/gitlab - these require special servers that are limited in terms of storage space, even if you run them on premisis.
- GitHub currently enforces a 2 GiB size limit per-object, even with LFS
- On github, beyond 1GB, you have to pay extra
git-annex is more flexible, but more challenging to work with and configure. And both git-lfs and git-annex suffer from a final, a major issue:
[they use] Git’s smudge and clean filters to show the real file on checkout. Git only stores that small text file and does so efficiently. The downside, of course, is that large files are not version controlled: only the latest version of a file is kept in the repository.
Whilst DVC doesn’t drop into projects as easily as the above options, it does offer improvements on the limitations of those tools. Furthermore, DVC offers key features (pipelines and reproducibility) which those alternatives do not include at all.
Where DVC Can and Can’t Help
DVC offers a significant improvement in the following areas:
- Managing large datafiles in ML systems
- Effective reproducibility in ML systems
- Team onboarding and code sharing efficiency
- Reduction in tooling and hacking required for ML system cohesion
- Performing and tracking experiments
DVC is not a silver bullet. It can’t help you with:
- Overall system design
- Effective collaboration between teams, i.e. ensuring that silos between data science/product/engineering
- Figuring out your dependencies in the first place
- Failure to manage runtime dependencies and OS-level reproducibility issues (this is where containerization can help).
- Controlling non-deterministic behaviour
- Operations that read directly from a changing datastore and do not save intermediate files (DVC does provide a strong reason to add these files though)
But none of these are surprising, and nor would they be expected.
DVC Risks
After my brief test, two key risks with DVC came to mind:
1. False sense of security
There is the risk that you configure your pipeline incorrectly, forgetting to add an output file or a dependency, and then assume your system is working correctly when DVC repro does not warn you about any issues. DVC’s ASCII renderings of pipeline steps can help, but particularly while a team is getting used to the tool, mistakes could be made. Team members might also forget about corner cases and assume their DVC checked out version of a project will work exactly as it did a year ago, which may not be the case if features are generated based on the current time or if random seed have not been fixed.
I am not sure how one would go about testing DVC pipeline steps to check for missing dependencies which would not throw an error - a common problem in ML systems is that standard unit/integration tests simply do not detect anything wrong because mistakes in feature engineering/data munging do not trigger errors. Such mistakes just result in incorrect, but perfectly plausible, model predictions. One mitigating technique that comes to mind is the use of differential tests and shadow deployments, but these would catch bugs relatively late in the deployment process.
2. Process Mistakes
DVC is easy to pick up for anyone who uses Git, due to similarities in concepts and commands. Having said that, it does not seamlessly integrate into Git, DVC commands have to be run in addition to Git commands. The docs say that you run dvc push “along with git commit and git push to save changes to .dvc files to Git.” I do worry this is something I (or a colleague) might forget. In this aspect, DVC is not as simple as git-lfs, which integrates into your git workflow and does not require extra commands once setup. As a result, we have the risk that new data files that are not tracked via Git are neglected and not added to DVC due to a breakdown in communication/failure to understand a new tool. Clearly, this risk can be mitigated through process and training. It would be nice if it could also mitigated through tooling, perhaps with Git pre-commit hooks that automatically checked for any required DVC commands. I can see in the DVC repo that this is a feature under consideration.
Closing Thoughts
Overall, I’m impressed with the Data Science Version Control system. Its large file management functionality is useful on its own, and when combined with its Pipelines and Reproducibility features DVC offers a lot of value. Note that I did not even cover DVC’s experimentation capabilities, which may be of interest to those operating more in the research environment.
I’m undecided as to whether the reproducibility functionality in my example project would be enough for me to switch to DVC, but I can definitely imagine a project where I could have more input data or intermediate output files in the data preparation process. Such a project would benefit enormously from DVC pipelines and reproducibility. Also, my current project relies heavily on scikit-learn pipelines, which mitigate some (though not all) of the challenges DVC Pipelines address. However, where engineers are working with less mature tooling and/or languages, its possible that these sorts of pipelines would not be available and in those cases DVC would be an easy drop-in.
DVC is well worth exploring by data scientists and engineers struggling with the challenges and demands of modern machine learning systems.