Top 10 Software Development Fundamentals for Data Scientists
What does the modern data scientist need to know?
Introduction
Drew Conway famously created this Venn diagram of skills for a data scientist.
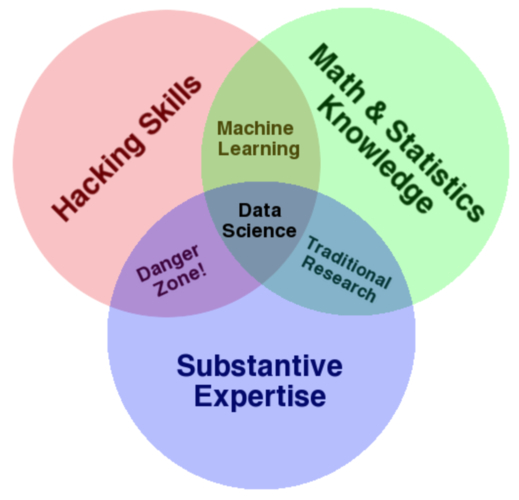
Now, the “Maths/Statistics” and “Substantive Expertise” sections of this diagram are quite self-explanatory. But what exactly are “hacking skills?” Here, Conway is using “Hacking” in the positive sense of the word, not the criminal sense:
For better or worse, data is a commodity traded electronically; therefore, in order to be in this market you need to speak hacker. This, however, does not require a background in computer science—in fact—many of the most impressive hackers I have met never took a single CS course. Being able to manipulate text files at the command-line, understanding vectorized operations, thinking algorithmically; these are the hacking skills that make for a successful data hacker.
In this post, I will unpick some of the fundamental elements within the umbrella term “Hacking Skills” which are most important for data scientists. I’ll also spend some time considering the confusing overlap between different bits of terminology.
Contents
Fundamental 1: Written English
Fundamental 2: At least one relevant programming language
Fundamental 4: Version Control
Fundamental 5: Familiarity with your Operating System
Fundamental 7: Data Visualization
Fundamental 8: Reproducibility and Dependency Management
Fundamental 10: Systems Understanding
Why Should You Care?
There are many data scientists out there who through their excellent stats knowledge or domain expertise, are able to “do” data science for many years with pretty rudimentary hacking skills. And in a lot of companies, they will be cut quite a bit of slack by software engineers because of the other skills they bring to the table.
The purely technological part of data science - installing things, getting things in and out of databases, version control, db and cluster administration etc. - may seem like a boring chore to you […] This type of thinking is a mistake. – Nadbor Drozd
By neglecting the “boring” programming skills, data scientists can end up being:
- Far less efficient with data preparation tasks
- Slower to iterate and test new ideas
- Stuck on relatively trivial setup issues (“how do I update my PYTHONPATH again?”)
- Unable to work with larger data sets that do not fit on their laptop
- A drain on their colleagues in engineering who have to completely re-write the code from the research environment because it is either not modular, or just plain sloppy. In some cases this can be a deal breaker and mean that a data scientist’s work never makes it into production!
This is not to mention the fact that most data science interviews in today’s market will also include some programming questions. Hopefully the value of the “hacking” set of skills to the modern data scientist is clear. Let’s unpack these skills.
Terminology Bonanza: Programming, Software Engineering and Hacking.
Time to get our terms straight. I like this breakdown of programmer/hacker/developer:
Programmers solve problems using code, a Hacker is a creator/tinkerer, and a Developer is a formally trained programmer
- All hackers and developers are programmers.
- Many programmers, and even developers, are not creative enough to be considered hackers.
- Many programmers, and even hackers, are not educated or experienced enough to be considered developers.
We can consider the terms “developer” and “software engineer” as equivalent (a decade ago, one might have argued that a software engineer had a formal education, but nowadays so many software engineers are self-taught/go through bootcamps that I think that distinction is outdated). We can also consider the terms “coder” and “programmer” to be equivalent.
Phew! That’s a lot of pedantry. An important point to note is that “Software Engineering” also includes a lot of theory on how to effectively collect requirements, estimate workloads, collaborate effectively, and to test & maintain complex systems. A lot of that is just project management combined with domain expertise, which is applicable to many disciplines. So we won’t focus on it - many of those skills are equally important for data scientists, but also for builders, civil engineers and event managers etc.
What do we mean by “fundamentals”?
If a “hacking skill” changes depending on a data scientist’s domain or industry, then it probably isn’t a “fundamental” skill. For example, not all data scientists need to work with “Big Data” (however you choose to define that) in order to improve the quality and efficiency of their work, so I don’t think that working with Hadoop and Spark (as well as knowledge of distributed systems) is a fundamental skill for a data scientist. Now don’t get me wrong - for many data scientists, knowing about these technologies will be an extremely useful skill. But since a for a significant proportion of practitioners it is not necessary, then those skills do not make the “fundamental” cut. On the other hand, the ability to use version control (such a git), will improve the efficiency of a data scientist in virtually every field, making it a fundamental skill. With that distinction in mind, we will explore these fundamentals in more detail.
Note that I am not including so-called “soft skills”, such as creativity, communication, collaboration, and problem solving. These are obviously important as well (many would argue more important), but not the focus of this post.
Fundamental 1: Written English
The majority of programming languages, libraries, tools and frameworks have their documentation written in English, the source code comments are overwhelmingly in English and the majority of guides, tutorials and answers on sites such as stackoverflow are in English. Whilst there are significant open source contributions, forums and software tools dedicated to speakers of other languages, for example the Alibaba cloud ecosystem is mostly tailored towards Mandarin speakers, these are still significantly outnumbered by materials written in English. Therefore, without the ability to read English, a data scientist will severely hinder their ability to maximize their programming (as well as other) capabilities.
Fundamental 2: At least one relevant programming language
We won’t be having this discussion

A data scientist needs to know a programming language to be effective. Not just any programming language, but one which lends itself to data science tasks - through an ecosystem which makes performing machine learning, numerical analysis and data munging comparatively simple. In practice, this boils down to one of the following:
- Python
- R
- Java
- Scala
- Julia
- SAS
- MATLAB
In addition to any one of the above languages, SQL is a must-have, which gets its own section later.
For a comparison of the pros and cons of these languages, see this article. Regardless of which of the above languages you focus on, a solid understanding of the basics within that language (and also in abstract) are crucial:
- Data structures
- Variables
- Loops
- Functions
- Basic performance considerations
A decent understanding of the relevant data science-related libraries and tools for that particular language (i.e. its data science “ecosystem”) is also key to being effective. For example in Python these would be the likes of numpy, pandas and scikit-learn.
Language Paradigms
Part of knowing a language includes understanding the programming paradigms for that language. Most high-level languages (such as Python), support all of these paradigms, at least to a certain degree.
Source: The Data Science Handbook by Field Cady
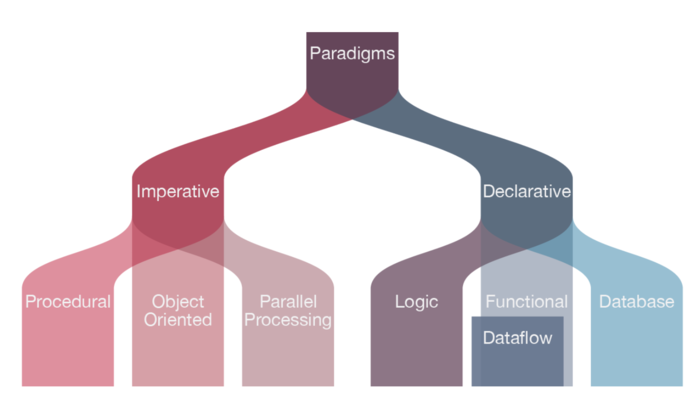
A basic familiarity with different approaches, such as an object oriented design vs. an imperative or a functional approach, is an important part of being an effective programmer. This is a awareness that can improve the code quality of the vast majority of data scientists.
Fundamental 3: Basic SQL
Eventually, data ends up in a database of some kind. The ability to query that data is a fundamental skill for a data scientist worth their salt. Make no mistake though, this is a complex area: The role of a Database Administrator (DBA) exists for a reason - you can spend an entire career specializing and becoming an expert in one particular flavor of database system (MSSQL, Postgresql, Oracle etc.) Therefore, in terms of fundamentals for data scientists, it’s familiarity with:
- Data Manipulation Language Commands: INSERT, SELECT, UPDATE, DELETE
- Data Definition Language Commands: CREATE, USE, ALTER, DROP
- Joins
Without these SQL basics, a data scientist will be unable to easily tap into an organization’s data, instead relying on others to slice and dice this data for them. This is highly inefficient, and also a missed opportunity for understanding how a company stores and structures its data which can lead to additional insights and improvements in and of itself.
Fundamental 4: Version Control
Version control, AKA Source Control, is vital. For me, the lack of a version control system (VCS) is the number one sign of an amateurish software project. This stackoverflow answer nails the benefits:
Have you ever:
- Made a change to code, realised it was a mistake and wanted to revert back?
- Lost code or had a backup that was too old?
- Had to maintain multiple versions of a product?
- Wanted to see the difference between two (or more) versions of your code?
- Wanted to prove that a particular change broke or fixed a piece of code?
- Wanted to review the history of some code?
- Wanted to submit a change to someone else’s code?
- Wanted to share your code, or let other people work on your code?
- Wanted to see how much work is being done, and where, when and by whom?
- Wanted to experiment with a new feature without interfering with working code?
A version control system is the answer to each of these questions. A common misconception is the version control is only useful when you are working in teams. In fact, it is still extremely valuable when you are working alone, allowing you to explore alternative approaches and quickly revert back if one avenue of investigation doesn’t work out.
In 2019 the dominant version control system is git, but there are other players such as SVN and Mercurial. Note that git is not the same as github - github serves as a cloud platform for code storage and collaboration, with the underpinning version control used on your code being your preferred version control system. Competitors to github include bitbucket and gitlab.
As a data scientist, you are negatively impacting your productivity by failing to leverage a version control system. You are also making it harder to collaborate with others.
Fundamental 5: Familiarity with your Operating System
Regardless of whether you (and perhaps more importantly, your company) use Windows, OS X or Linux, you should be at least somewhat of a “power user” of your chosen system. This means:
- You can easily manipulate environment variables
- You can write and run a basic script on your OS - bash for Linux/OS X and powershell for Windows.
- You can perform basic operations via the command line: searching, moving and modifying files, creating directories etc.
- You know how to connect to other machines remotely to perform the above sort of operations (i.e. via ssh or PuTTY)
Fundamental 6: Testing
Some data scientists view testing as a low-value activity, which isn’t worth their time. This couldn’t be further from the truth. Testing is one of those deceptive activities which takes more effort in the short-term, but in the long-term is a huge time-saver. Having a unit or integration test to check a particular step in your data preparation pipeline can save you hours of searching for the bug a month later, when you are much further removed from the context and can barely remember how that particular step works. If your test is well written, it will present you with the exact location (or at least a very strong clue) where you can look to fix the bug. Key areas to gain familiarity for data scientists include:
- The testing module for your language of choice
- Different types of testing and when to use them (The Google SRE Book is a great place to learn about this)
Testing is a complex area, which many software engineers never completely master. But it’s an area where even a small amount of time spent learning can pay huge dividends over the course of a career.
Fundamental 7: Data Visualization
Source: Axis Group
A significant part of the data scientist’s job is presenting data and results to tell a story. Visualizing this data elegantly and clearly can make the difference between persuading management to try an idea or not - so being able to create powerful and convincing visualizations is a key part of a data scientists arsenal.
Most programming languages have libraries for charting and visualizing, often many of them. It’s important that you are familiar with at least one, so that you don’t have to interrupt your flow state to lookup documentation on how to create a certain type of chart. Being able to effortlessly chart as you explore a data set can allow a data scientist to see patterns faster, allowing them to either abandon or pursue an idea further. Over a career, this can represent weeks of saved time.
Fundamental 8: Reproducibility and Dependency Management

Reproducibility is the ability to duplicate a model exactly such that given the same raw data as input, both models return the same output. This sounds simple, but can be an extremely challenging part of data science as data scientists attempt to replicate predictions from the research environment to the development/production environment. Errors in reproducibility result in increased financial costs as work has to be redone, lost time and frustration and potentially reputational damage if there is an error in production. Furthermore, without the ability to replicate prior results, it is difficult to determine if a new model is truly better than the previous one. A few areas required for effective reproducibility include:
- Code dependency management (including external libraries)
- Strict model versioning
- Data dependency versioning and management
- Modular and reproducible data preparation and feature engineering pipelines
This is a super important area for modern data scientists. Here’s a joint-talk I gave with Soledad Galli on this topic at the London Data Science Festival. We also cover this topic extensively in our Udemy Course on Deployment of Machine Learning Models.
Fundamental 9: Debugging
If you are unable to debug your code effectively, you are going to work incredibly inefficiently. This means that at least a cursory understanding of the following are fundamental skills:
- Debugging tools provided by the language (e.g. the pdb module in Python)
- Understanding how to read stack traces
- Familiarity with common sorts of syntax errors and exceptions
- Ability to use tools to assist with debugging (e.g. breakpoints in an IDE)
- Googling skills!
Being able to resolve errors quickly as the crop up will massively improve a data scientist’s productivity. Plus it is satisfying.
Fundamental 10: Systems Understanding
This final area is deliberately vague. A data scientist needs to be able to understand, at least roughly, how their models fit in the overall production system. What sort of testing will their models go through? How will the models be deployed by their colleagues in engineering? How will the results from the model be monitored and stored? An understanding of how these sorts of challenges are being tackled allows a data scientist to add a huge amount of value, by doing things such as:
- Identifying data that should be captured (for example, in order to guarantee reproducibility), which their colleagues in engineering might otherwise miss
- Understanding the challenges in shifting models from the research to the production environment so that they can help improve collaboration and reduce the chances of bugs between the different environments.
- Creating ML-specific tests and/or creating the input datasets required for these sorts of tests, such as differential and benchmark tests.
- Paying attention to the feedback from model monitoring so that they can quickly suggest iterations and improvements to existing models
- Have an appreciation for the time it takes to make significant or minor changes to the system, and prioritize their models accordingly This doesn’t mean that a data scientist needs to have the knowledge of a software architect, but an appreciation for how a system works allows a data scientist to maximize their contribution.
Naturally, there are always more things to learn, more skills to add. But a data scientist who has a strong grasp on these 10 fundamentals is a huge asset, and a formidable individual.
Go on, write some tests ;)