Leveraging Open Source Models for AI Evaluation with DeepEval
Crossing the Chasm from Toy to Production Application - AI Evaluation
Welcome to part 5 of this AI Engineering with open-source models tutorial series. Click here to view the full series.
Post Sections
1. Introduction to AI Evaluation Challenges
2. AI Evaluation Metrics
3. Introducing DeepEval: A Framework for AI Evaluation - Code starts here
4. DeepEval in Action: Evaluating a Simple Language Model
5. Closing Thoughts
Introduction to AI Evaluation Challenges
Once you have a basic grasp of the possibilities of LLM applications, there comes the difficult work of effectively harnessing that power.
AI applications can misbehave in weird and wonderful ways which traditional software systems do not. This means that our LLM evaluation approach needs to adapt.
Evaluation of generated results can be difficult, since unlike traditional machine learning the predicted result isn’t a single number, and it can be hard to define quantitative metrics for this problem. - LlamaIndex docs
Evaluation Metrics
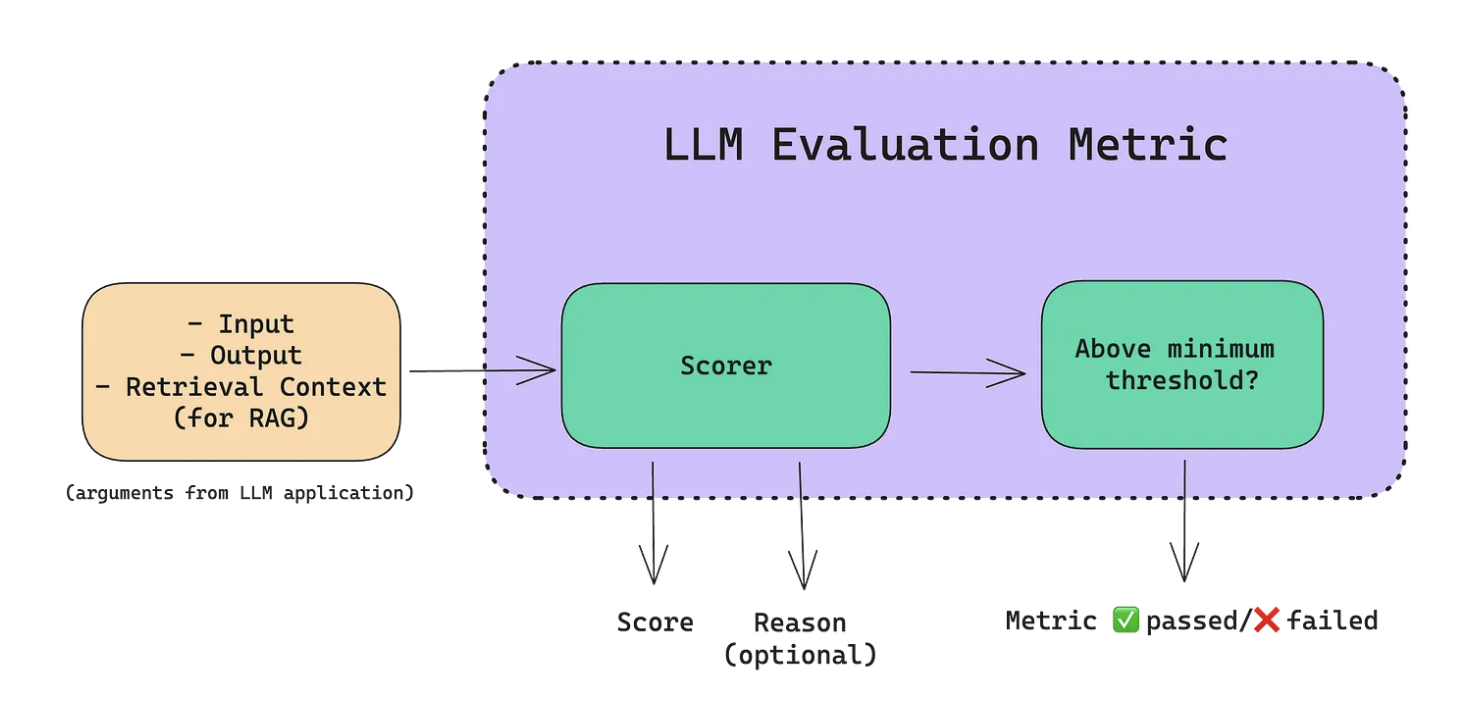
Concretely, applications can:
- Suffer from hallucinations
- Struggle to keep up-to-date with the latest information
- Respond with irrelevant information
- Respond with correct but suboptimal information (like, the second biggest reason for something instead of the biggest)
- Totally lie to you
- Return toxic or dangerous content you wouldn’t want to share with your users
- Surface secret content you don’t want to unveil (often via chatbot prompt jailbreaking)
As if that wasn’t enough, the fundamental process of selecting the next “best” token by LLMs is probabilistic, meaning they can produce different outputs for the same input due to their non-deterministic nature.
As you can probably infer, we need a good solution to these potential issues. Manually checking outputs a few times isn’t going to cut it. Even if you iterate over your prompts and evaluate them in a for loop. Yes, even then dear reader.
To address these challenges, we define model evaluation metrics. These are not to be confused with traditional
observability metrics (like latency, or HTTP error rates). These model metrics can compared with old-school
ML metrics:

Except, we now have much more complexity to deal with. Let’s roll up our sleeves and consider it all.
Types of AI Evaluation Metrics
In a typical AI application, the areas of evaluation fall into two main areas:
- Response Evaluation: Does the response match the retrieved context? Does it also match the query? Does it match the reference answer or guidelines?
- Retrieval Evaluation: Are the retrieved sources relevant to the query?
These in turn can be broken down further. Here’s a streamlined overview:
Using NLI Models:
You can evaluate factual accuracy with Natural Language Inference (NLI) models, which provide an entailment score. The higher the score, the more factually correct the response is considered. This is especially useful for nuanced outputs.
Evaluation References
In the evaluation context, a “reference” is external, verified information used to assess the accuracy or relevance of a model’s output by serving as a factual or conceptual benchmark. However, not all metrics require references. Metrics such as:
- Relevancy
- Bias
- Toxicity
- Helpfulness
- Harmlessness
don’t require external references. They evaluate outputs based on the content itself.
Metrics such as:
- Factual correctness
- Conceptual similarity
require comparison to a provided context, so references are required for these types of evaluation metrics.
RAG Evaluation
Retrieval-Augmented Generation (RAG) systems use metrics like contextual recall and precision for the retriever, and answer relevancy and faithfulness for the generator.
LLMs all the Way Down
There’s a new emerging trend to use state-of-the-art (such as GPT-4) LLMs to evaluate themselves or even other others LLMs.
G-Eval is a recently developed framework that uses LLMs for evals. This technique can be incredibly powerful, and is likely the direction of travel for the industry.
Regardless of which metrics we select, we still have the tough challenge of computing some kind of metric score. The methods for calculating these scores fall into two distinct camps: statistical methods and model-based methods:
Statistical Scorers
- BLEU
- ROUGE
- METEOR
- Levenshtein Distance
Model-Based Scorers
- QAG Score
- GPTScore
- SelFCheckGPT
- GEval
- Prometheus
- BERTScore
- MoverScore
- NLI
- BLEURT
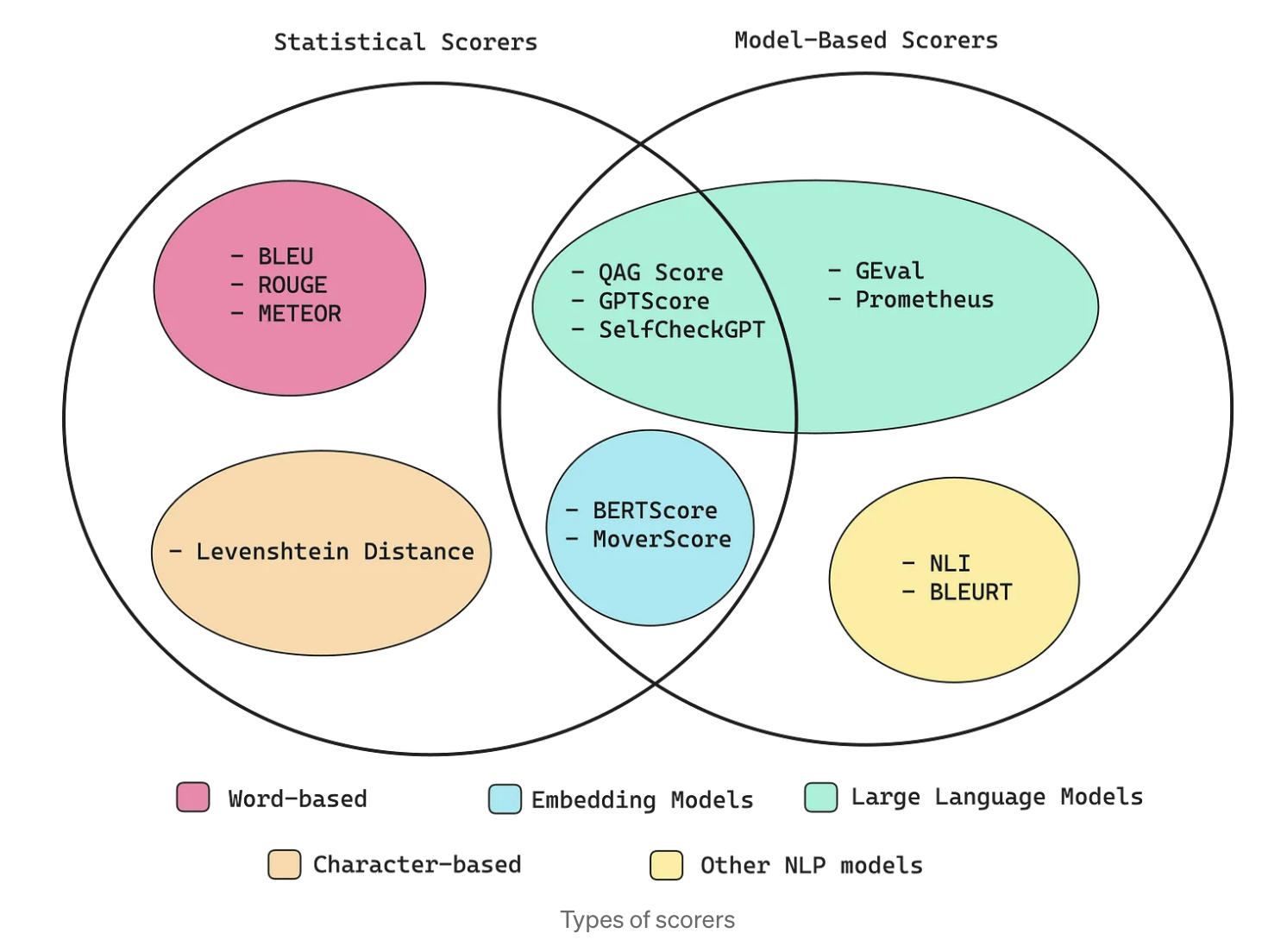
For a longer exploration of these approaches check out this article.
Purely statistical scoring methods offer simplicity and reliability, yet they lack the capacity for nuanced reasoning and semantic analysis. On the other hand, scorers utilizing NLP models deliver greater accuracy and sophisticated reasoning but can be less consistent due to their probabilistic design.
Choosing the right metrics depends on your application and architecture. However, we can be prescriptive about some things: If you have a RAG pipeline, you definitely will want:
- Faithfulness
- Answer Relevancy
- Contextual Precision
The QAG Scorer is the best scorer for RAG metrics since it excels for evaluation tasks where the objective is clear. source
Steps to Create an Evaluation Process
- Create an evaluation dataset
- Identify relevant metrics for evaluation
- Develop a Scorer to calculate metric scores, bearing in mind that outputs from large language models (LLMs) are probabilistic. Therefore, your Scorer’s implementation should acknowledge this aspect and avoid penalizing outputs that, while different from anticipated responses, are still correct.
- Apply each metric to your evaluation dataset
- Improve your evaluation dataset over time
Setting up an evaluation framework in this way enables you to:
- Run several nested for loops to find the optimal combination of hyperparameters such as chunk size, context window length, top k retrieval etc.
- Determine your optimal LLM - especially important when evaluating open-source LLMs
- Determine your optimal embedding model
- Iterate over different prompt templates that would yield the highest metric scores for your evaluation dataset (although note that prompts won’t perform the same across different models, so always group prompts and models together)
The Rise of Open-Source Models in AI Evaluation
Given the rising popularity of LLM-based evaluation metrics like G-Eval, we can now start to use open-source LLMs in an evaluation capacity also. If you would like a primer on how to use open-source models, check out the post on this topic. Recent advancements have made open-source models increasingly viable for evaluating AI applications. This is extremely powerful because it means we can run our test suites without paying OpenAI, Anthropic or any other external LLM service for the privilege. It also means we get to keep our data private (particularly important when evaluating RAG pipelines).
The rest of this article will show you how to do this in practice.
Introducing DeepEval: A Framework for AI Evaluation
In the Retrieval Augmented Generation (RAG) part of this tutorial series, we introduced the popular LlamaIndex. LlamaIndex offers a few community evaluation tool integrations:
I was drawn to DeepEval for a few reasons:
- It is open-source
- It works with your existing Python pytest suite of tests
- It offers a wide variety of evaluation metrics
- The source code is readable
- It works with open-source models
- The cofounder of confident-ai (who make DeepEval) - Jeffrey Ip is very helpful and responsive
I don’t have any affiliation with the product, but it was the sort of thing I was looking for.
DeepEval offers a range of default metrics for you to quickly get started with, such as:
- General Evaluation (G-Eval - define any metric with freetext)
- Summarization
- Faithfulness
- Answer Relevancy
- Contextual Relevancy
- Contextual Precision
- Contextual Recall
- Ragas
- Hallucination
- Toxicity
- Bias
DeepEval in Action: Evaluating a Simple Language Model
Here’s an example of using DeepEval to evaluate a large language model (LLM) using open-source models.
We’ll create a test case we can run with the rest of our pytest suite:
# test_llm.py
import json
from deepeval import assert_test
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
from llama_cpp import Llama
def test_model_outputs():
# Given
short_transcript = "A short transcript snippet which talks about semi-conductor supply chain fragmentation."
llm = Llama(
model_path="path/to/your/gguf/model/mistral-7b.gguf",
n_ctx=32000,
n_batch=8, # tweak this for your hardware
chat_format="mistral-instruct",
)
system_prompt = (
"Summarize this transcript in a JSON output with keys 'title' and 'summary'"
)
user_prompt = f"{system_prompt}: {short_transcript}"
actual_output = llm.create_chat_completion(
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
],
max_tokens=-1, # use n_ctx
temperature=0.1,
)
output = json.loads(actual_output["choices"][0]["message"]["content"].strip())
# When
test_case = LLMTestCase(
input=short_transcript,
actual_output=output["summary"],
expected_output="fragmented nature of the supply chain and existing monopolies",
context=[short_transcript],
)
# Metric 1: Hallucination
# uses vectara's hallucination evaluation model
hallucination_metric = HallucinationMetric(threshold=0.7)
assert_test(test_case, [hallucination_metric])
In the above example, our open-source model is run locally with the llama.cpp Python bindings, as I showed
in part 3
of this tutorial series. We generate an output from this model, and pass when we instantiate an instance of
the LLMTestCase. Since we’re not yet testing a RAG pipeline, the context is the same as the input.
We then instantiate the HallucinationMetric, giving it a score threshold which the test must pass. Under the hood,
this particular metric downloads the vectara hallucination model
from HuggingFace.
Finally, we use DeepEval’s assert_test method, passing in our test case and a list of metrics (in this case, just the hallucination
metric). We can run this test with: pytest test_llm.py.
A More Complex Example
What if we want to define a custom evaluation metric? We can use G-Eval:
G-Eval is a custom, LLM evaluated metric. This means its score is calculated using an LLM. G-Eval is the most verstile type of metric deepeval has to offer, and is capable of evaluating almost any use cases.
For scenarios where you are working wtih an API like OpenAI’s (GPT-4) or Anthropic (Claude), you would specify a G-Eval like so:
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCaseParams
my_metric = GEval(
name="insights",
model='gpt-4', # API usage
threshold=0.5,
evaluation_steps=[
"Determine how good the summary of the transcript is"
],
evaluation_params=[LLMTestCaseParams.INPUT, LLMTestCaseParams.ACTUAL_OUTPUT],
)
Defining the metric in this way will require you to set you OpenAI API key, and will result in API calls to evaluate your LLM. In our case, we want to use our open-source models to do our evaluation as well. This gives us:
- More control of the model configuration
- Keeps our data private
- Does not cost us any money
The docs caution against doing this because:
Evaluation requires a high level of reasoning capabilities that we find are generally not reachable apart from […] OpenAI’s GPT models.
But given the rapid rise in quality of open-source models, such as the release of the Mistral Mixture of Experts (Mixtral) model, I think this advice is likely to go out of date rapidly. Furthermore, a significant reason for giving this advice is to do with ensuring outputs are in a particular format (e.g. JSON), which we can do by using formal grammars. Nonetheless, proceed with reasonable caution.
In order to use our open-source models, we need to leverage the CustomEvaluationModel.
Here’s what that looks like:
import json
from deepeval import assert_test
from deepeval.metrics import GEval
from deepeval.models import DeepEvalBaseModel
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
from llama_cpp import Llama, LlamaGrammar
class CustomEvaluationModel(DeepEvalBaseModel):
def __init__(self, model):
self.model = model
def load_model(self):
return self.model
def load_grammar(self) -> LlamaGrammar:
file_path = "path/to/grammar/filellama.gbnf"
with open(file_path, "r") as handler:
content = handler.read()
return LlamaGrammar.from_string(content)
def _call(self, prompt: str) -> str:
chat_model: Llama = self.load_model()
response = chat_model.create_completion(
prompt, max_tokens=256, grammar=self.load_grammar()
)
return response["choices"][0]["text"]
def get_model_name(self):
return "Custom Open Source Model"
def test_model_outputs():
# Given
short_transcript = "A short transcript snippet which talks about semi-conductor supply chain fragmentation."
llm = Llama(
model_path="path/to/your/gguf/model/mistral-7b.gguf",
n_ctx=32000,
n_batch=8, # tweak this for your hardware
chat_format="mistral-instruct",
)
custom_deep_eval_model = CustomEvaluationModel(model=llm)
system_prompt = (
"Summarize this transcript in a JSON output with keys 'title' and 'summary'"
)
user_prompt = f"{system_prompt}: {short_transcript}"
actual_output = llm.create_chat_completion(
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
],
max_tokens=-1, # use n_ctx
temperature=0.1,
)
output = json.loads(actual_output["choices"][0]["message"]["content"].strip())
# When
test_case = LLMTestCase(
input=short_transcript,
actual_output=output["summary"],
expected_output="fragmented nature of the supply chain and existing monopolies",
context=[short_transcript],
)
# Metric: Insights
insights_metric = GEval(
name="insights",
model=custom_deep_eval_model,
threshold=0.5,
evaluation_steps=[
"Determine how entertaining the summary of the transcript is"
],
evaluation_params=[LLMTestCaseParams.INPUT, LLMTestCaseParams.ACTUAL_OUTPUT],
)
assert_test(test_case, [insights_metric])
In the snippet above, we ensure that our CustomEvaluationModel:
- Inherits from the
DeepEvalBaseModel - Implement the load_model() method, which will be responsible for returning a model object.
- Implements the _call() method with one and only one parameter of type string that acts as the prompt to your custom LLM.
In the above example I used the same mistral-7b model for both the metric model and the system model. You could also use different models.
Closing Thoughts
No one wants to pay to run their test suite. Open-source evaluation is a really powerful tool, and I expect to see a lot more adoption of it in the coming months. It’s unclear at the moment how the economics will work with running machines capable of doing inference with open-source models in say, CI pipelines. But at least for the lone developer working on their laptop, here lies a beacon of freedom from the tyranny of API costs.