Production RAG with a Postgres Vector Store and Open-Source Models
Going beyond storing your index in flat files
Welcome to part 6 of this AI Engineering open-source models tutorial series. Click here to view the full series.
Table of Contents
- Caution: Advanced Material Ahead
- Retrieval Augmented Generation (RAG) Overview
- PostgreSQL and pgvector
- Integrating RAG and Postgres Vector Store in Django (Detailed)
- Step 1: Setup the Django Project
- Important Side Note: Embedding Model Dimensions
- Step 2: Run the migrations
- Step 3: Loading Data For Our RAG Pipeline from PostgreSQL
- Step 4: Indexing to PGVectorStore with Open-Source Models
- Step 5: Setup the PGVectorStore
- Step 6: Create the ServiceContext
- Step 7: Create the VectorStoreIndex
Caution: Advanced Material Ahead
- Don’t know the difference between fine-tuning and inference? Read my introduction to LLMs
- Don’t know what Retrieval Augmented Generation (RAG) is? Read my RAG post
- Don’t know how to use open-source models? Read my Llama.cpp post
Ready? Let’s go.
Retrieval Augmented Generation (RAG) Overview
A RAG pipeline is what allows your AI model(s) to leverage the knowledge of your private/corporate data in its inference. It consists of the following stages:
- Loading - Rustling up your data (e.g. from PDFs, slack, email, databases)
- Indexing - Making it easy to query the loaded data. For LLMs, this means creating vector embeddings
- Storing - Storing the index you created in the previous step for easy use
- Querying - Selecting information from your indexed data
- Evaluation - Figuring out if the previous steps suck or not
In this post we’re going to look at steps 1-4, but in particular step 3: Storing.
The main tool in the Python ecosystem for building RAG pipelines is LlamaIndex which I gave an overview of in my first RAG post. The more I use it, the more I am growing to like it. I think the team has found the right abstraction level. Unlike LangChain, which has not.
What’s an Index?
A data structure designed to enable querying by an LLM. In LlamaIndex terms, this data structure is composed of Document objects.
What’s a Vector Store Index?
The Vector Store Index is the predominant index type encountered when working with
Large Language Models (LLMs). Within LlamaIndex, the VectorStoreIndex data type processes
your Documents by dividing them into Nodes and generating vector embeddings for the text within
each node, preparing them for querying by an LLM.
Why Care About Index Storage?
When the vector embeddings are created in step 2 (indexing) of the RAG pipeline, the function calls to create the embeddings can be expensive in terms of time and money, so you will want to store them to avoid having to constantly re-index whenever a new query arrives. If you’re using open-source models for the embedding then money isn’t a worry, but time definitely is. And time is money.
Also, a not-so-well-known embedding model gotcha is that to compare two texts, both must be embedded with the same model. So if say, OpenAI deprecates an embedding model - like they did for all their “first generation text embedding models”, then you now have to reindex all your RAG data. Dang.
All this is to say that storing your indexed data is important.
The Basic Index Storage
When you first start going through the LlamaIndex docs, or looking at tutorials online,
you will overwhelmingly find
the basic file storage example. This means loading the index from flat JSON files via the load_index_from_storage
function from LlamaIndex:
from llama_index import SimpleDirectoryReader, VectorStoreIndex, load_index_from_storage, StorageContext, ServiceContext
# See the earlier posts in this series on how to get the llm and embedding models
# You could also use the ChatGPT API for this if you wanted to pay
service_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embedding_model,
system_prompt='You are a bot that answers questions about podcast transcripts'
)
storage_context = StorageContext.from_defaults(persist_dir=index_dir)
index = load_index_from_storage(storage_context, service_context=service_context)
This simple approach reads a collection of previously saved JSON files from disk uses them to load the index:
Great for experimentation. Not suitable for production because:
- It’s slow: Searching through embeddings stored in files requires loading the entire dataset into memory and then computing distances (e.g., cosine similarity) between the query vector and all stored vectors. This approach is inherently inefficient, especially as the dataset grows, leading to slow search times. Vector data stores are designed to optimize search operations through indexing mechanisms (e.g., k-d trees, HNSW graphs, etc.) that allow for efficient nearest neighbor searches.
- Concurrency & Access: Handling concurrent read and write operations is challenging with file-based storage, leading to potential data corruption.
- Data Management: Basic operations like updating or deleting vectors can be cumbersome and inefficient, often requiring rewriting the entire file.
- It won’t scale - think lack of efficient data partitioning, limited distribution mechanisms.
This is why LlamaIndex supports a high number of vector stores (or vector databases) which vary in complexity and cost.
PostgreSQL and pgvector
There are many, many options for vector stores with LlamaIndex:
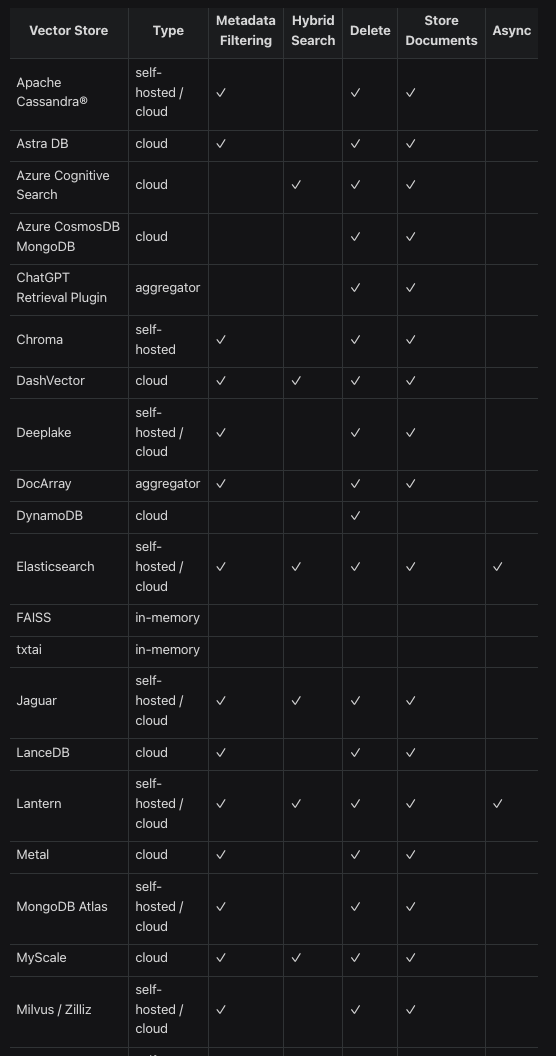
Most developers hadn’t heard of a vector database until about a year ago:

There are various tradeoffs between all of these options, none of which we’re going to discuss in this blog post. And in fact, sometimes the most exciting vector database proves a hassle - see this interesting write up on migrating away from pinecone back to postgres. But there is one answer that shines true, and should make your heart sing:
Just use Postgres
That’s right. LlamaIndex supports Postgres via the Postgres Vector Store. Postgres has the pgvector extension. This allows you to store vector embeddings alongside the rest of your production system data. It supports:
- Exact and approximate nearest neighbor search
- L2 distance, inner product, and cosine distance
- Any language with a Postgres client
- Plus ACID compliance, point-in-time recovery, JOINs, and all of the other great features of Postgres
This means that you don’t have to spend one of your precious innovation tokens on a vector DB, and can stick with battle-tested boring technology. Obviously if you have some advanced use-case go for it. But if you’re still figuring things out, you probably shouldn’t prematurely optimize.
Integrating RAG and Postgres Vector Store in Django
Here’s a full example in Django. If you want an example in FastAPI, then check out my course. But seriously, use Django, it’s the best (and Django-ninja gives it FastAPI-like type hints).
Step 1: Setup the Django Project
I’m going to gloss over some basic Django details, but fundamentally you need:
- Some ORM data models
- DB Migrations
- A couple of custom Django commands
Create your virtualenv, do your pip install, create your Django project. Install PostgreSQL. Hook up
Django to it. Then here are our example data models:
models.py
from django.conf import settings
from django.db import models
from pgvector.django import VectorField
class Episode(models.Model):
title = models.CharField(max_length=255)
episode_number = models.IntegerField()
date_published = models.DateTimeField()
class Transcript(models.Model):
episode = models.OneToOneField(Episode, on_delete=models.CASCADE)
content = models.TextField()
embedding = VectorField(dimensions=settings.EMBEDDING_MODEL_DIMENSIONS, null=True)
last_updated = models.DateTimeField(auto_now=True) # Automatically updates to current time on save
Important things to note here:
- We’re using the pgvector-python library, specifically
the
VectorField - We setup the notion of podcast episodes and related transcripts.
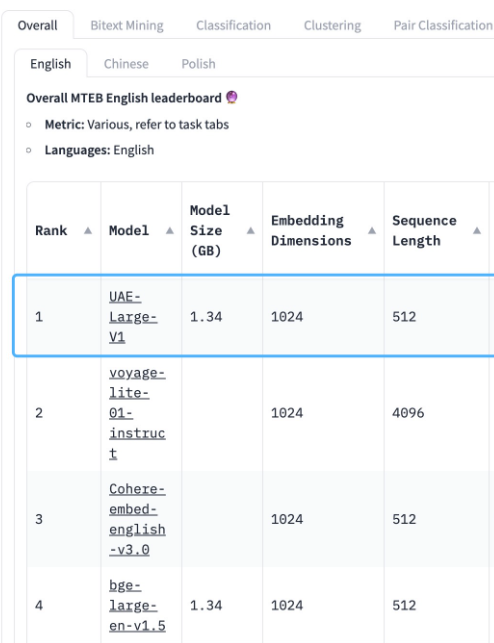
Important Side Note: Embedding Model Dimensions
No matter which vector store you are using, you need to know how many dimensions your
embedding model uses. In this tutorial I’m using the UAE-Large-V1 from HuggingFace
Typically, HuggingFace will display the embedding dimensions on the model card. You need to
know this information - it varies from one model to another and if you get it wrong then
you will end up sad.
Step 2: Run the migrations
You need to create a manual DB migration (do python manage.py makemigrations --empty yourappname)
to create the pgvector extension. Populate your migration as described in the python-pgvector docs:
your_migration_file.py
from django.db import migrations
from pgvector.django import VectorExtension
class Migration(migrations.Migration):
dependencies = [
('your_app_name', '000n_whatever_other_migration_you_have'), # autogenerated
]
operations = [
VectorExtension() # add this - it creates your PG extension
]
Now run:
python manage.py migrate
If your postgres user doesn’t have superuser access, this command will fail. This is annoying and there doesn’t seem to be a clear consensus on the most secure way to do this. I granted perms to the user, ran the command, then switched them off.
Now generate the rest of your migrations (autogenerated from your models.py file):
python manage.py makemigrationspython manage.py migrate
OK! We’re ready to fetch our data.
Step 3: Loading Data For Our RAG Pipeline from PostgreSQL
n.b. There was an huge LlamaIndex PR merged when they released v0.10.0 To ensure the code snippets below work, use version 0.9.x.
Assume you have saved some transcripts in your DB (a reasonable course of action). You can now
use LlamaIndex’s DataBaseReader to load that data (step 1 of a RAG pipeline):
from llama_index import (
download_loader,
Document,
)
def fetch_documents_from_storage(query: str, parsed_url) -> list[Document]:
# Prep documents - fetch from DB
DatabaseReader = download_loader("DatabaseReader")
reader = DatabaseReader(
scheme="postgresql", # Database Scheme
host=parsed_url.hostname, # Database Host
port=parsed_url.port, # Database Port
user=parsed_url.username, # Database User
password=parsed_url.password, # Database Password
dbname=parsed_url.path[1:], # Database Name
)
return reader.load_data(query=query)
The parsed_url argument contains our database connection string information. The query
is a SQL query, which we prepare now:
query = f"""
SELECT e.episode_number, e.title, t.content
FROM transcriber_episode e
LEFT JOIN transcriber_transcript t ON e.id = t.episode_id;
"""
documents = fetch_documents_from_storage(query=query, parsed_url=parsed_url)
In this way, we prepare a load of LlamaIndex Document objects from data in our Postgres
database. No more flat files - we are now in the realm of production datasets.
Step 4: Indexing to PGVectorStore with Open-Source Models
To purely save the vector embeddings for future use (for things like semantic search via cosine similarity), we can proceed like so:
import re
from llama_index.embeddings import HuggingFaceEmbedding
from llama_index import Document
from .models import Transcript, Episode
# You would cache this
EMBED_MODEL = HuggingFaceEmbedding(
model_name="WhereIsAI/UAE-Large-V1", embed_batch_size=10 # open-source embedding model
)
def save_embeddings(documents: list[Document]) -> None:
for document in documents:
match = re.match(r"^(\d{1,3})", document.text)
if match:
episode_number = int(match.group(1)) # Convert to int for exact matching
# Fetch the episode using get() for a single object
episode = Episode.objects.get(episode_number=episode_number)
transcript = Transcript.objects.get(episode=episode)
# Generate and save the embedding
embedding = EMBED_MODEL.get_text_embedding(document.text)
transcript.embedding = embedding
transcript.save()
save_embeddings(documents=documents) # documents loaded previously
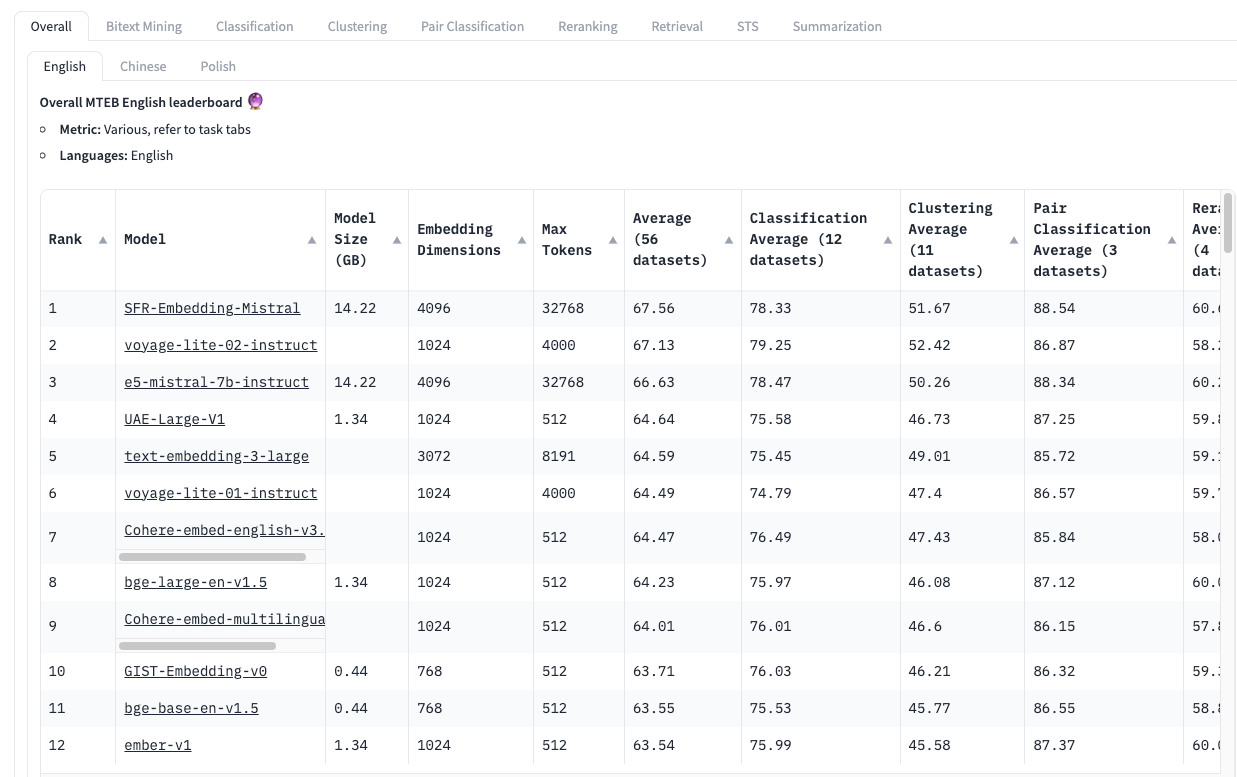
Notice in the above snippet, we download the open-source UAE-Large-V1 model from HuggingFace.
There is actually a leaderboard just for embedding models: The Massive Text Embedding Benchmark (MTEB) Leaderboard
We save the generated embeddings to the transcript table using the standard Django models save syntax.
After running this command, if we look at our Transcript table we will find the embeddings
populated:

Nice! We will make further use of these embeddings next.
Step 5: Setup the PGVectorStore
Now we start to use postgres as our vector database. The first time we want to use LlamaIndex to generate an index we can then
query, we will first create our PGVectorStore:
from urllib.parse import urlparse
from llama_index.vector_stores import PGVectorStore
from django.conf import settings
# settings are omitted for brevity, but a Postgres URL looks like this:
# postgresql://username:password@hostname:port/databaseName
db_url = settings.DB_URL
parsed_url = urlparse(db_url)
vector_store = PGVectorStore.from_params(
database=parsed_url.path[1:],
host=parsed_url.hostname,
password=parsed_url.password,
port=parsed_url.port,
user=parsed_url.username,
table_name="podcast_embeddings",
embed_dim=settings.EMBEDDING_MODEL_DIMENSIONS, # Must match your embedding model
)
Some noteworthy gotchas for the above command:
- This will create a new database table, which will be the
table_nameyou give it prepended with data_. So after running the above command I will have a table calleddata_podcast_embeddings. This doesn’t seem to be well-documented. - Under the hood, LlamaIndex is using
pgvectorbut also (at least in v0.9.x), sqlalchemy, asyncpg github, and psycopg2-binary pypi - these extra libraries are not installed by default with llama-index, so you may need to install manually.
Step 6: Create the ServiceContext
At this point, we have “primed” our vector store, now we need to create the VectorStoreIndex which uses the table
we just generated to store the vector embeddings. This process requires us to have a LlamaIndex ServiceContext (at
least in <=0.9.x). This encapsulates both our open-source embedding model and our open-source LLM:
from llama_index.llms import LlamaCPP
from llama_index.embeddings import HuggingFaceEmbedding
from llama_index import set_global_tokenizer, ServiceContext
from transformers import AutoTokenizer
llm = LlamaCPP(
model_path="path/to/your/GGUF/model", # Download the GGUF from hugging face
context_window=30000, # Tune to your model - Mixtral 8x7b is a beast.
max_new_tokens=1024,
model_kwargs={"n_gpu_layers": 1}, # >=1 means using GPU. 0 means using CPU.
verbose=True,
)
embed_model = HuggingFaceEmbedding(
model_name="WhereIsAI/UAE-Large-V1", embed_batch_size=10 # open-source embedding model
)
set_global_tokenizer(
AutoTokenizer.from_pretrained(f"mistralai/Mixtral-8x7B-Instruct-v0.1").encode) # must match your LLM
service_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
system_prompt="You are a bot that answers questions in English.",
)
Some things to note from the above snippet:
- Both the embed model and the Large Language Model in the service context are local open-source models downloaded from HuggingFace. You
could not specify one or the other, and LlamaIndex will then attempt to use its defaults - which are calls to the
text-embedding-ada-002(via OpenAI API calls) for embeddings and GPT 3.5 Turbo (also via OpenAI API calls) for LLM calls. - When working with the
LlamaCPPyou need toset_global_tokenizerto be compatible with your open-source LLM. Use theAutoTokenizerclass from the transformers library to assist with this.
Now that we have our service_context, we can bring everything together
Step 7: Create the VectorStoreIndex
We will make use of all the data, objects and setup we have performed in the previous steps in the below snippet:
from llama_index import (
ServiceContext,
VectorStoreIndex,
StorageContext,
Document,
)
from llama_index.vector_stores import PGVectorStore
def generate_vector_store_index(
vector_store: PGVectorStore,
documents: list[Document],
service_context: ServiceContext,
) -> VectorStoreIndex:
storage_context = StorageContext.from_defaults(vector_store=vector_store)
return VectorStoreIndex.from_documents(
documents,
storage_context=storage_context,
service_context=service_context,
show_progress=True,
)
index = generate_vector_store_index(
documents=documents, # We fetched these in step 3
service_context=service_context, # We prepped this in step 6
vector_store=vector_store, # We prepped this in step 5
)
query_engine = index.as_query_engine(
similarity_top_k=3,
)
response = query_engine.query(f"Who is Dylan Patel?")
In the above snippet, when we run generate_vector_store_index, all the documents passed in are embedded using
the open-source embedding model we put in the ServiceContext. They are then saved into the PostgreSQL table we
created in the vector_store.
Once we create the query engine, whenever we send a query, it goes through the whole RAG pipeline. Under-the-hood the prompts will be injected with relevant contextual information found from our podcast transcripts. As a result, the chatbot/application/service will be aware of the podcast-specific information we had stored in our database.
All this is done using open-source models, without a single call to a third-party service.
Later, when we wish to access the index again (without embedding our data again, which would be very inefficient), we simply run:
index = VectorStoreIndex.from_vector_store(
vector_store=vector_store, service_context=service_context
)
And the index will be ready as soon as the DB query completes.
Phew, that was a lot! If you get stuck, send me an email. I reply to interesting questions.
For more detailed examples, full code, and an example project, checkout: Building AI Applications with Open-Source Models