Running Open Source LLMs In Python - A Practical Guide
Unleashing AI Power on Your Laptop
Welcome to part 3 of this AI Engineering tutorial series. Click here to view the full series.
Table of Contents
1. Installation & Setup
2. Selecting and Downloading a Model
3. Using Your Model with llama.cpp Locally
4. Prompt Setup
5. Formatting LLM Output With GBNF Grammar
6. Streaming Responses
7. Multi-model Modals
8. Summary
The creation of open source Large Language Models (LLMs) is a huge opportunity for new kinds of application development. Not having to share proprietary data with a third parties like OpenAI (chatgpt) or Anthropic (Claude) means that many companies that previously would have been hesitant/unable to use AI now can do so. But until recently, running an LLM locally was a significant challenge due to heavy hardware requirements.
Fortunately, this is rapidly changing with the advent of projects like:
Under the hood, all these projects are leveraging quantized models, which reduces
memory requirements, making it feasible to run large models on consumer-grade hardware.
It’s now possible to run state-of-the-art (non-proprietary) Large Language Models (LLMs) on a reasonable modern
laptop. This post shows you how to do that with llama.cpp in Python, using the Python bindings
I’m going to focus on using llama.cpp because:
- LLaMa.cpp was developed by Georgi Gerganov who is a coding badass, (he also maintains ggml and whisper.cpp)
- It implements the Meta’s LLaMa architecture in efficient C/C++
- It is one of the most dynamic open-source communities around LLM inference with hundreds of contributors, and 50000+ stars on the official GitHub repository.
- It supports MacOS, Windows and Linux…but it especially loves MacOS which is what I use.
- It works with loads of open-source models - more on this later
- It integrates well with other AI engineering tools like Llama Index and LangChain
Installation & Setup
MacOS
“Metal” refers to Apple’s graphics API that is used for rendering graphics on devices running macOS. Metal provides near-direct access to the GPU (Graphics Processing Unit), which means that LLM inference is faster. Check out my LLM intro if you’re not sure what inference is, and how it differs from fine-tuning.
- You need xcode installed. You can check if it is installed with
xcode-select -p. If you get a path back as a response, then you’re good. Otherwise install it:xcode-select --install(warning: this takes ages) - On macOS, make sure you have these environment variables set to enable GPU support (which runs things faster):
CMAKE_ARGS="-DLLAMA_METAL=on" - Now
pip install llama-cpp-pythonor if you use poetrypoetry add llama-cpp-python
Windows/Linux
Check out the build instructions for Llama.cpp and make sure you have set the correct environment variables for your OS. For Windows users there is a Useful guide here
n.b. You can also run Llama.cpp in a Docker container and interact with it via HTTP calls. Guide here
Selecting and Downloading a Model
You can browse and use any model on Hugging Face which is in the GGUF format.
GGUF is a file format for storing models for inference with GGML and executors based on GGML. GGUF is a binary format that is designed for fast loading and saving of models, and for ease of reading. Models are traditionally developed using PyTorch or another framework, and then converted to GGUF for use in GGML.
A user called TheBloke (Tom Jobbins - a bit of legend on Hugging Face) has created GGUF versions of most of
the open-source models on the leaderboard. For example, here’s his version of
Mixtral-8x7B-Instruct. Linux and Windows
users may be able to also use GPTQ models like this one
but as a MacOS user I haven’t explored them.
The art of choosing the right model is obviously a vast area. But here are some pointers:
-
Check out the Chatbot Arena Leaderboard and look for models with an open license (e.g. Apache 2.0, Llama 2 Community, MIT):
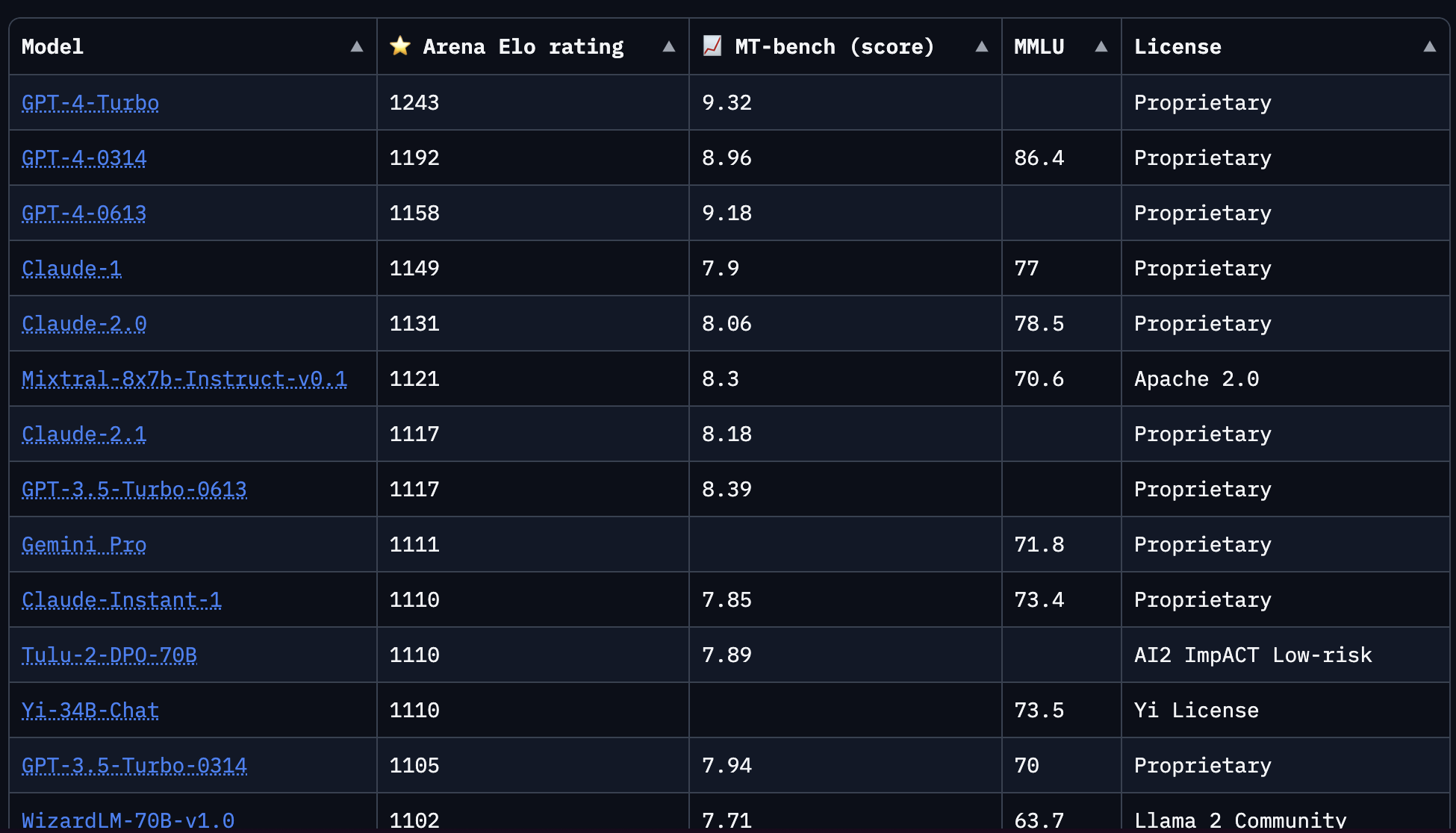
-
Find the
Instructversion of the model in GGUF format on Hugging Face Why theinstructversion? As per the Mistral Release blog postWe release Mixtral 8x7B Instruct alongside Mixtral 8x7B. This model has been optimised through supervised fine-tuning and direct preference optimisation (DPO) for careful instruction following. On MT-Bench, it reaches a score of 8.30, making it the best open-source model, with a performance comparable to GPT3.5.
emphasis added
- Look at the RAM requirements for different quantization amounts and download a model suitable for your machine
llama.cpp is compatible with almost all the major open-source LLMs:
- LLaMA 🦙
- LLaMA 2 🦙🦙
- Falcon
- Alpaca
- GPT4All
- Chinese LLaMA / Alpaca and Chinese LLaMA-2 / Alpaca-2
- Vigogne (French)
- Vicuna
- Koala
- OpenBuddy 🐶 (Multilingual)
- Pygmalion/Metharme
- WizardLM
- Baichuan 1 & 2 + derivations
- Aquila 1 & 2
- Starcoder models
- Mistral AI v0.1
- Refact
- Persimmon 8B
- MPT
- Bloom
- Yi models
- StableLM-3b-4e1t
- Deepseek models
- Qwen models
- Mixtral MoE
- PLaMo-13B
- GPT-2
The Mixtral-8x7B model is the current (January 2024, the rankings change frequently) best performing general purpose LLM. It has pretty high compute requirements:
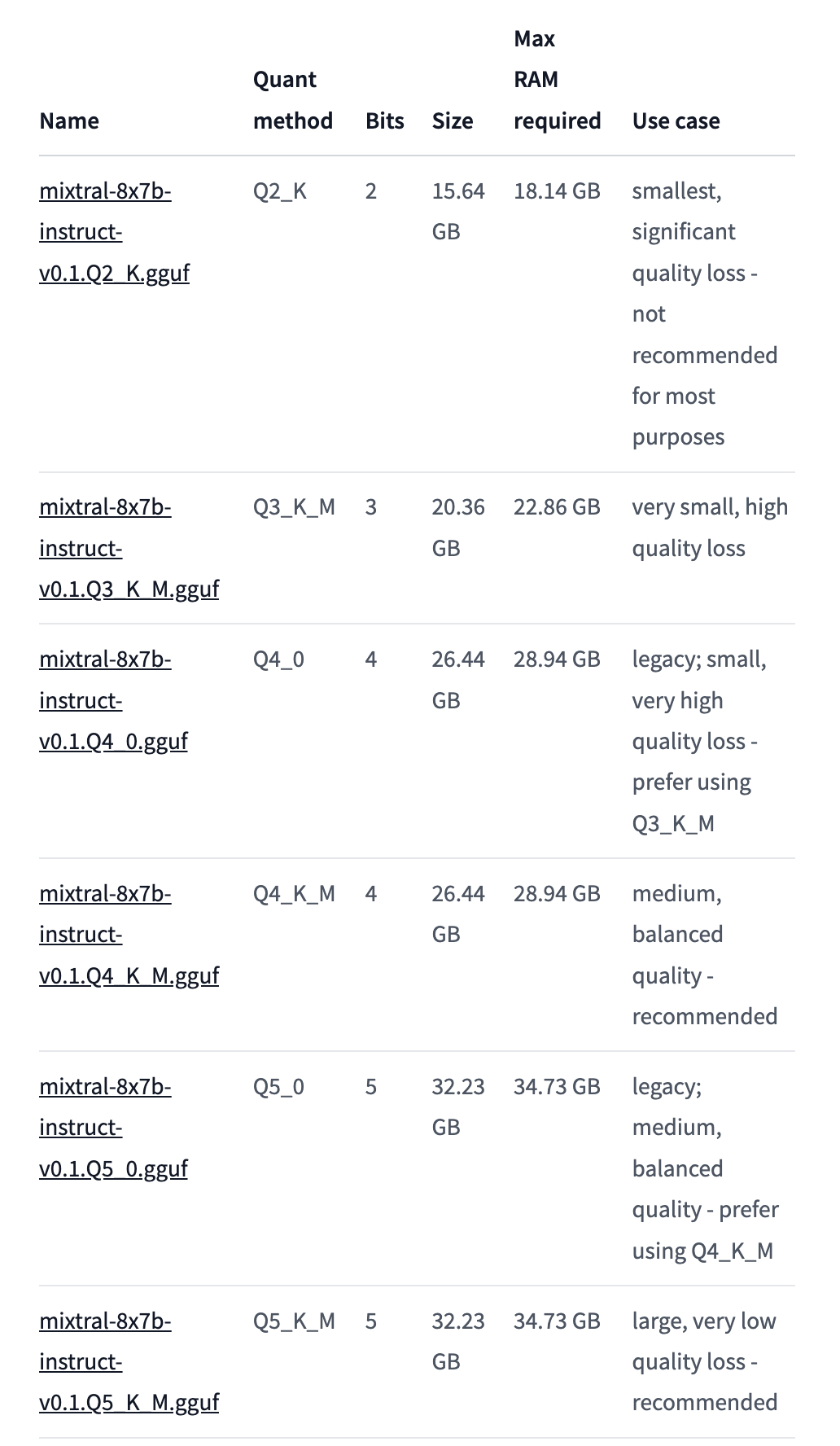
But my new Macbook can cope with these. If you’ve got an older machine, a less demanding but still decent model you could check out would be Llama-2-7b
You can download the raw files from the Files tab in Hugging Face. Alternatively you can use the Hugging Face CLI.
Using Your Model with llama.cpp Locally
Once you’ve downloaded the model you can instantiate the Llama model object like so:
from llama_cpp import Llama
llm = Llama(model_path="path/to/your/download/Mixtral_8x7B_Instruct_v0.1.gguf")
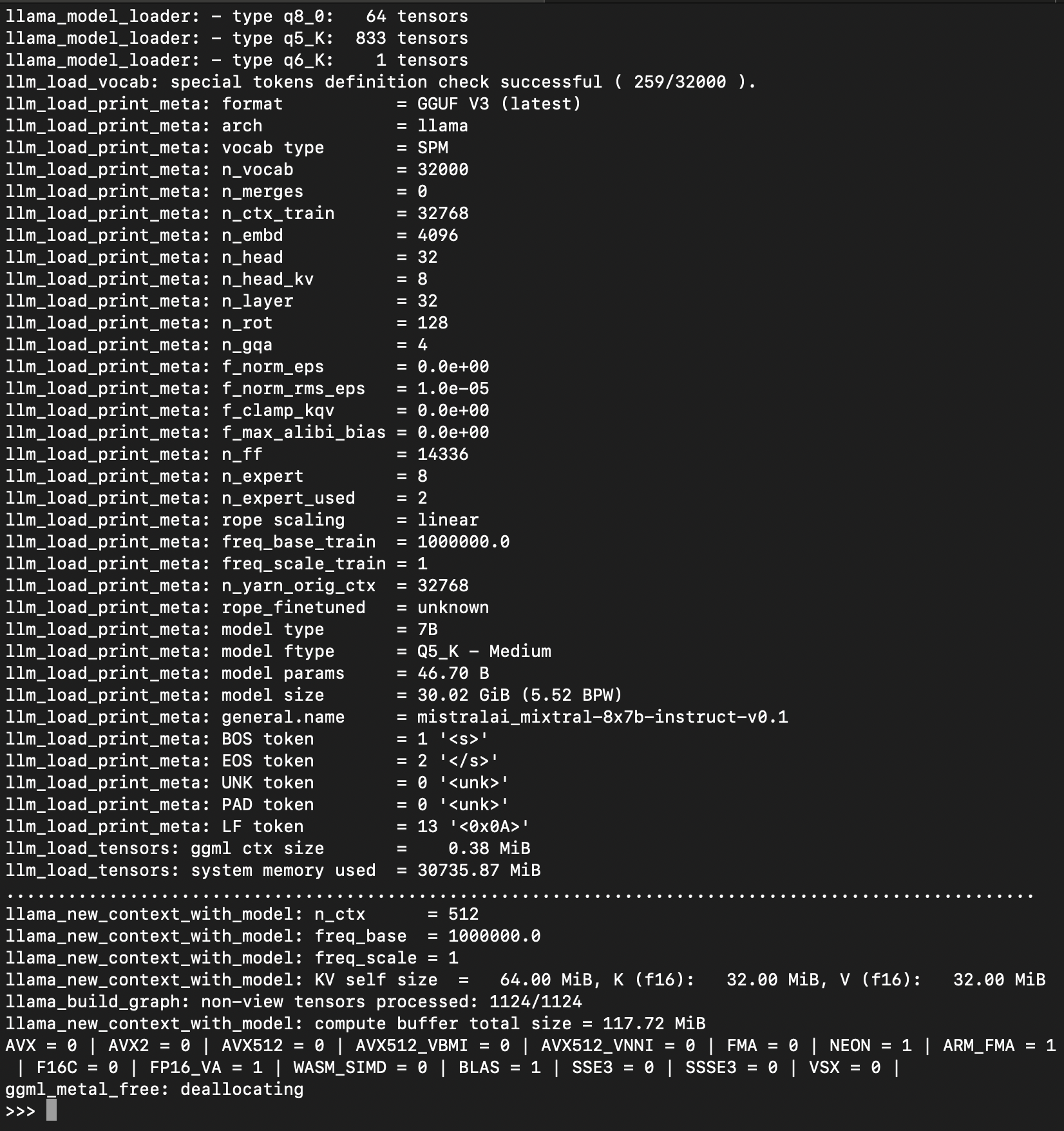
You will see the model loading information if you run this in the python interpreter:
Enabling GPU Support
The problem with the approach above is that by default llama.cpp will use your system CPU.
This will work, but will be slower. To enable GPU usage we will instantiate our
Llama object with the n_gpu_layers argument set:
from llama_cpp import Llama
llm = Llama(model_path="path/to/your/download/Mixtral_8x7B_Instruct_v0.1.gguf", n_gpu_layers=1)
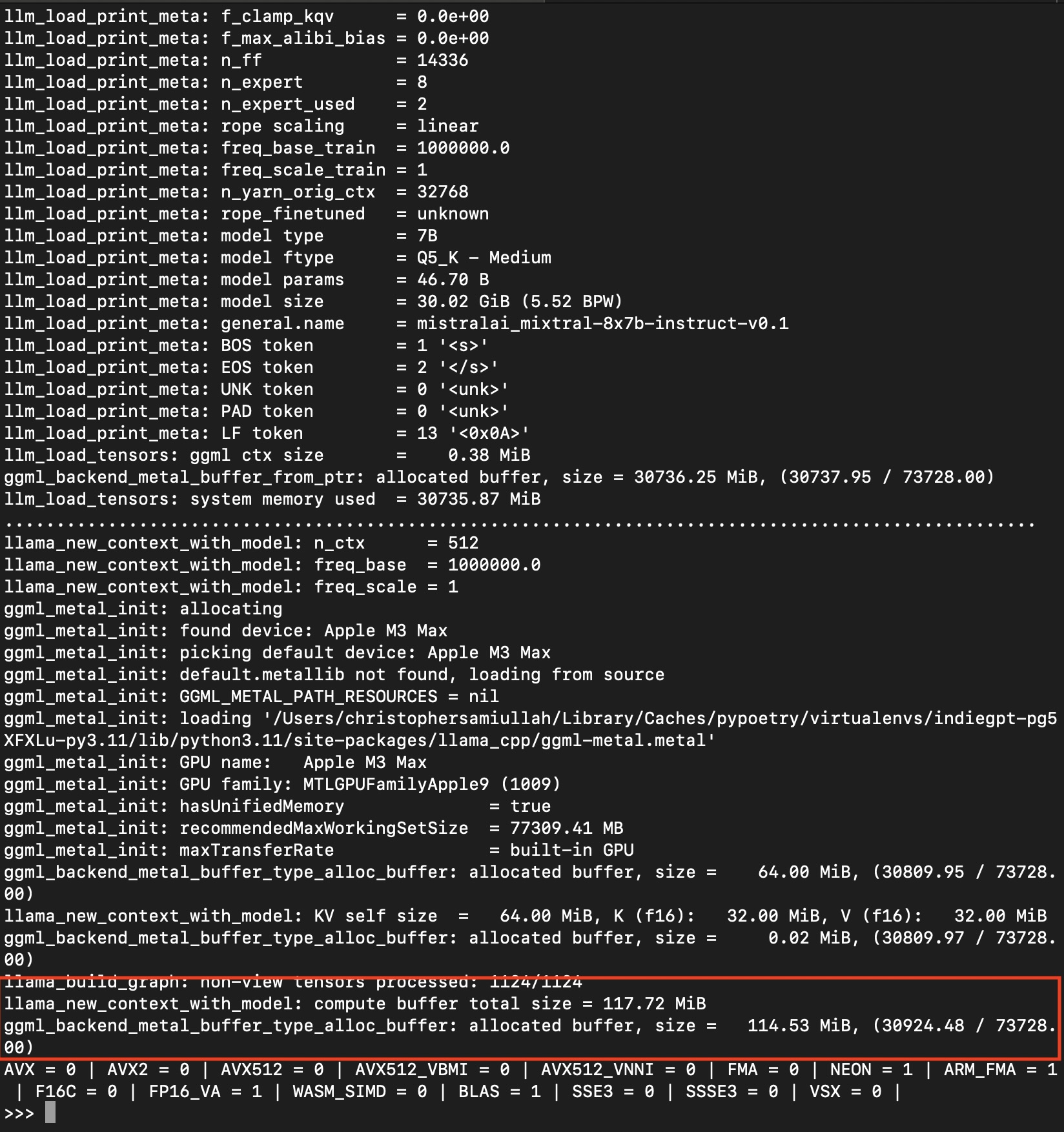
This time around, note the ggml_backend_metal_buffer_type_alloc_buffer line, which indicates we are ready
to use the GPU. This will be different on Windows/Linux, so check according to your OS.
Great, you now have the model loaded and ready to do something. We will use the Python bindings high-level API for text completion. Let’s try it out:
output = llm(
"Q: What is the capital of France?", # Prompt
max_tokens=32, # Generate up to 32 tokens
stop=["Q:"], # Stop generating just before the model would generate a new question
echo=False # Do not Echo the prompt back in the output
) # Generate a completion, can also call create_completion
# Note that you have to dig into the output `choices` field to find the answer to
# your question.
print(output['choices'][0]['text'])
You should see the following output:
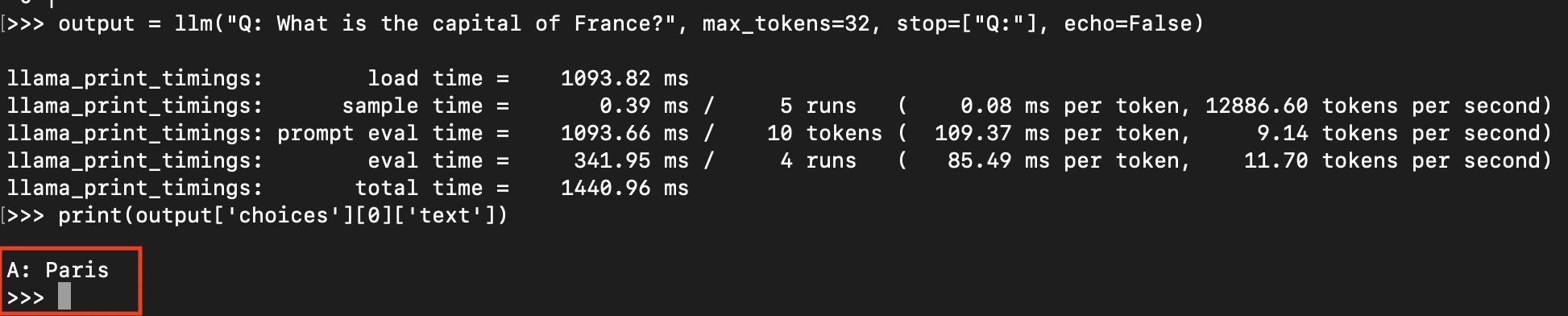
The local LLM has answered our question correctly without making any API calls! On my Macbook Pro (admittedly a beast with 96GB of RAM), this query took less than a second. Let that sink in.
Note that the above snippet is equivalent to running llm.create_completion, we’re just using
the __call__ method instead.
Is working with the __call__ method confusing to less experienced Python users: definitely.
Chat Completions
We can also use the create_chat_completion method (as opposed to the create_completion method)
for ongoing interactions. These are helpful for clearly differentiating between incoming user
prompts and baseline system instructions. Here’s an example, if we wish our responses to
be written in the style of Sir David Attenborough.
# We limit the output size with n_ctx
llm = Llama(model_path="./llm_models/Mixtral_8x7B_Instruct_v0.1.gguf", n_ctx=256)
output = llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are an assistant who responds in the style of Sir David Attenborough"},
{
"role": "user",
"content": "Tell me about giraffes."
}
]
)
# Note the output format changes for chat completions
print(output['choices'][0]['message']['content'])
Here is out Attenborough-esque result:

Adjusting the Context Window
The context window of the LLM determines the maximum number of tokens that can be processed at once. By default, this is set to 512 tokens, but can be adjusted based on your requirements.
Note in the above snippet, we instantiated the Llama object with n_ctx=256. In my
project I set max_tokens=-1 because any value less than 0 makes llama cpp just rely on
n_ctx. It seems that n_ctx is the key argument to define the size of your models output.
Now it’s a bit more complex than that, because to be more precise:
n_ctxis a parameter that defines the maximum number of tokens the model can consider from the input prompt when generating a response or completion.
Which means that your total n_ctx will also include the system prompt and the user prompt.
So you have to factor that in when considering this. You also have to make sure this value is
under the model’s own max context window threshold, which you can find from a given
model’s documentation:
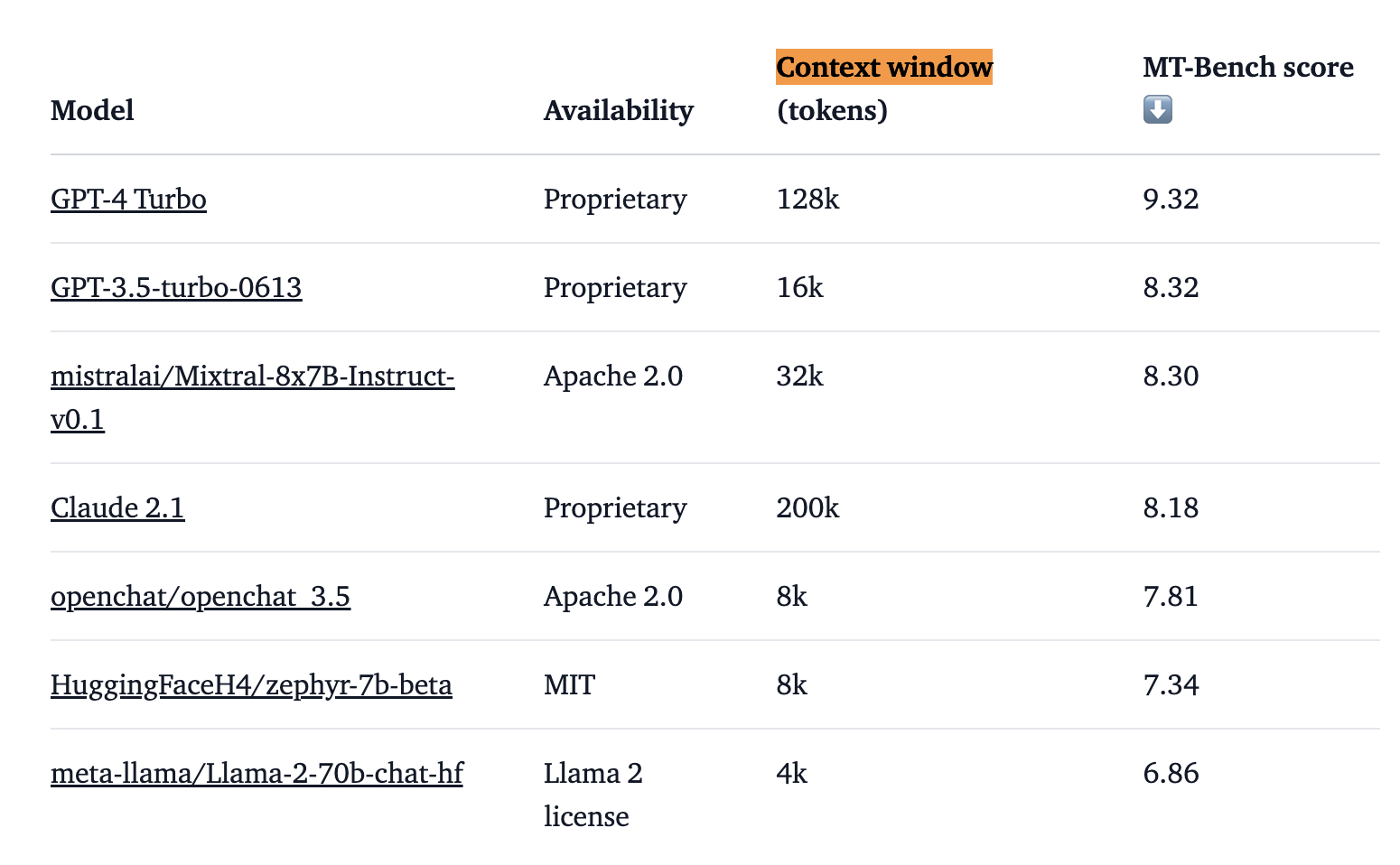
The good news is that models like Mixtral 8X7B have enormous context windows, handling up to 32k tokens. This means you can pass in very large amounts of text to the model without having to do painful map reduce combining of documents or do any Retrieval Augmented Generation (RAG).
Temperature
In the context of using llama.cpp with Python for a Large Language Model (LLM), you can adjust the temperature setting to control the creativity and randomness of the model’s responses. Here’s an example:
# Import Llama library
from llama_cpp import Llama
# Initialize the Llama model with a specified model path
llm = Llama(model_path="./llm_models/gpt3_model.gguf", max_tokens=128)
# Set the temperature for the model
temperature = 0.7 # A medium temperature for a balance between creativity and reliability
# Create a prompt and generate a completion
prompt = "Write a story about a lost treasure."
response = llm.create_completion(prompt, temperature=temperature)
print(response)
- We set the temperature to 0.7, which is a medium setting, balancing between predictable and creative responses.
- The prompt asks the model to write a story, a task where a bit of creativity is beneficial.
- The create_completion method generates a response based on the prompt and temperature settings.
Prompt Setup
Prompt engineering is a huge topic, here is a great guide. For our purposes, with a local open-source LLM, the key thing to note is:
Different models require different prompting formats.
Make sure your prompt format matches the format recommended by the model. Here is the format for Mixtral 8X7B:
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]
llama.cpp has a chat_format parameter (defaults to llama-2), which we can use with the Python bindings.
The chat formats are not well documented, but if you look at the source code you
can see the options in the llama_chat_format.py file
So you would instantiate the LLM with the chat_format set, here’s a deep investigation
of using different prompt formats.
Jinja Templates
I recommend putting your prompts into Jinja templates
Using Jinja templates for Large Language Model (LLM) prompts in applications offers several advantages:
- Dynamic Content Integration: Jinja templates allow for the incorporation of dynamic content into prompts, making them adaptable to varying user inputs or situations.
- Template Reusability: Templates can be reused across different parts of an application, ensuring consistency in prompt structures while allowing for customization based on context.
- Simplified Prompt Management: Managing and updating prompts becomes easier, as changes can be made in templates rather than in the code, enhancing maintainability.
- Complex Logic Handling: Jinja’s conditional statements and loops enable handling complex logic within prompts, accommodating more sophisticated and contextually relevant interactions.
- Scalability: As applications scale and prompts become more complex, Jinja templates help manage this complexity in an organized manner.
Suppose you’re building a chatbot for a weather application. You might have a Jinja template for a weather query like this:
{% set greeting = “Hello” if time_of_day == “morning” else “Good evening” %} {{ greeting }}, the weather in {{ location }} is currently {{ temperature }} degrees with {{ condition }}.
In this template:
- The greeting changes based on the time of day.
- The location, temperature, and weather conditions are dynamically inserted into the prompt.
- This single template can generate personalized weather reports for different users and conditions.
Formatting Your LLM Output with GBNF Grammars
An awesome feature of llama.cpp is formal grammars:
GBNF (GGML BNF) is a format for defining formal grammars to constrain model outputs in llama.cpp. For example, you can use it to force the model to generate valid JSON, or speak only in emojis.
I wanted one of my models to output valid JSON, so I specified a JSON schema in my prompt template like this:
system_prompt.md.j2 - A jinja template
When the user asks a question, provide an answer in the JSON format described below:
**Internal View - JSON Intake Full Schema**:
{
"type": "object",
"properties": {
"answer_summary": {
"type": "string",
"minLength": 25,
"maxLength": 100,
"description": "A brief summary of the results."
}
}
}
Then I fetch my grammar file:
from llama_cpp import LlamaGrammar
def get_grammar() -> LlamaGrammar:
file_path = "path/to/grammar/llama.gbnf"
with open(file_path, 'r') as handler:
content = handler.read()
return LlamaGrammar.from_string(content)
def load_prompt():
with open("path/to/prompt/system_prompt.md.j2", 'r') as file:
return file.read()
llm.create_chat_completion(
messages = [
{"role": "system", "content": load_prompt()},
{
"role": "user",
"content": "Tell me about giraffes."
}
],
stop=[],
grammar=get_grammar()
)
Now my outputs are guaranteed to be in JSON format - super useful!
Streaming Our Responses
Streaming responses with llama.cpp in Python involves setting up a process where the model generates
responses in a continuous, iterative manner, rather than producing a single,
one-off output. This is particularly useful for applications like chatbots or ongoing
text generation where the output needs to be delivered in a real-time or near-real-time manner.
Here’s a basic example to illustrate how you might set up streaming responses with llama.cpp in Python:
def stream_response(response_stream):
for partial_output in response_stream:
# Process each part of the response
print("Partial output:", partial_output['choices'][0]['text'])
prompt = "Write a story about a magical forest."
response_stream = llm.create_completion(prompt, stream=True)
stream_response(response_stream)
Multi-model Modals
Many are predicting that 2024 will be the “year of multi-modal models” (see this excellent Latent Space podcast episode for a detailed exploration of the topic). Llama cpp supports the llava1.5 family of multi-modal models which allow the language model to read information from both text and images:
- llava-v1.5-7b
- llava-v1.5-13b
- bakllava-1-7b
>>> from llama_cpp import Llama
>>> from llama_cpp.llama_chat_format import Llava15ChatHandler
>>> chat_handler = Llava15ChatHandler(clip_model_path="path/to/llava/mmproj.bin")
>>> llm = Llama(
model_path="./path/to/llava/llama-model.gguf",
chat_handler=chat_handler,
n_ctx=2048, # n_ctx should be increased to accomodate the image embedding
logits_all=True,# needed to make llava work
)
>>> llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are an assistant who perfectly describes images."},
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": "https://.../image.png"}},
{"type" : "text", "text": "Describe this image in detail please."}
]
}
]
)
Summary
Summary of Model Selection Tips
- Select a model size (i.e. quantization level) suitable for your hardware
- Use the
Instructversion - Make sure the model is in GGUF format
- Make sure you use a text generation model (not an embedding model)
Summary of Config Tips
- Install llama cpp with optimizations appropriate for your operating system
- Load the model with
n_gpu_layers=1to enable GPU support. - Ensure you carefully set your
n_ctxcontext window length, factoring in both the system prompt and user prompt - Use Jinja templates for your prompts
- Make sure your prompt format is correct for your model.
- Use grammars to control your LLM output format.
What About Deployment? Should I use this Technique In Production?
It heavily depends on your project and use-case. I’ll be writing more about this in the coming weeks so subscribe to the blog for loads of detailed analysis soon.
This is the start of an incredible renaissance for all kinds of software applications. The ability to safely synthesize large amounts of personal data has huge implications. The age of AI engineering is upon us like never before. I’m going to write about it a lot!