The Ultimate FastAPI Tutorial Part 9 - Asynchronous Performance Improvement
In part 9 of the FastAPI tutorial, we'll look at utilizing async IO to improve performance
Introduction
Welcome to the Ultimate FastAPI tutorial series. This post is part 9. The series is a project-based tutorial where we will build a cooking recipe API. Each post gradually adds more complex functionality, showcasing the capabilities of FastAPI, ending with a realistic, production-ready API. The series is designed to be followed in order, but if you already know FastAPI you can jump to the relevant part.
Code
Project github repo directory for this part of the tutorial
Tutorial Series Contents
Optional Preamble: FastAPI vs. Flask
Beginner Level Difficulty
Part 1: Hello World
Part 2: URL Path Parameters & Type Hints
Part 3: Query Parameters
Part 4: Pydantic Schemas & Data Validation
Part 5: Basic Error Handling
Part 6: Jinja Templates
Part 6b: Basic FastAPI App Deployment on Linode
Intermediate Level Difficulty
Part 7: Setting up a Database with SQLAlchemy and its ORM
Part 8: Production app structure and API versioning
Part 9: Creating High Performance Asynchronous Logic via async def and await
Part 10: Authentication via JWT
Part 11: Dependency Injection and FastAPI Depends
Part 12: Setting Up A React Frontend
Part 13: Using Docker, Uvicorn and Gunicorn to Deploy Our App to Heroku
Part 14: Using Docker and Uvicorn to Deploy Our App to IaaS (Coming soon)
Part 15: Exploring the Open Source Starlette Toolbox - GraphQL (Coming soon)
Part 16: Alternative Backend/Python Framework Comparisons (i.e. Django) (Coming soon)
Post Contents
Theory Section - Python Asyncio and Concurrent Code
Practical Section - Async IO Path Operations
Notes on Async IO and Third-Party Dependencies like SQLAlchemy
![]()
There are two main reasons why FastAPI is called “Fast”:
- Impressive framework performance
- Improved developer workflow
In this post, we’ll be exploring the performance element (1). If you’re comfortable with Python’s
asyncio module, you can skip down to the practical part of the post. If not, let’s talk
theory for a bit.
Theory Section - Python Asyncio and Concurrent Code
A quick bit of terminology. In programming, concurrency means:
Executing multiple tasks at the same time but not necessarily simultaneously
On the other hand, doing things in parallel means:
Parallelism means that an application splits its tasks up into smaller subtasks which can be processed in parallel, for instance on multiple CPUs at the exact same time.
More pithily:
Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once.
This stackoverflow thread has some great further reading in the answers/comments.
For years, options for writing asynchronous code in Python were suboptimal - relying on the limited
asyncore and asynchat modules (both now deprecated) or third-party libraries like gevent or Twisted.
Then in Python 3.4 the
asyncio library
was introduced. This was one of the most significant additions to the Python language in its history,
and from the initial PEP-3156 (well worth a read), there
were many subsequent improvements, such as the introduction of async and await syntax in
PEP-492. These changes to the language have resulted in a sudden
Python ecosystem renaissance, as new tools which make use of asyncio were (and continue to be) introduced,
and other libraries are updated to make use of the new capabilities. FastAPI and Starlette (which is the foundation
of FastAPI) are examples of these new projects.
By leveraging Python’s new Asynchronous IO (async IO) paradigm (which exists in many other languages), FastAPI has
been able to come up with very impressive benchmarks (on par with nodejs or golang):
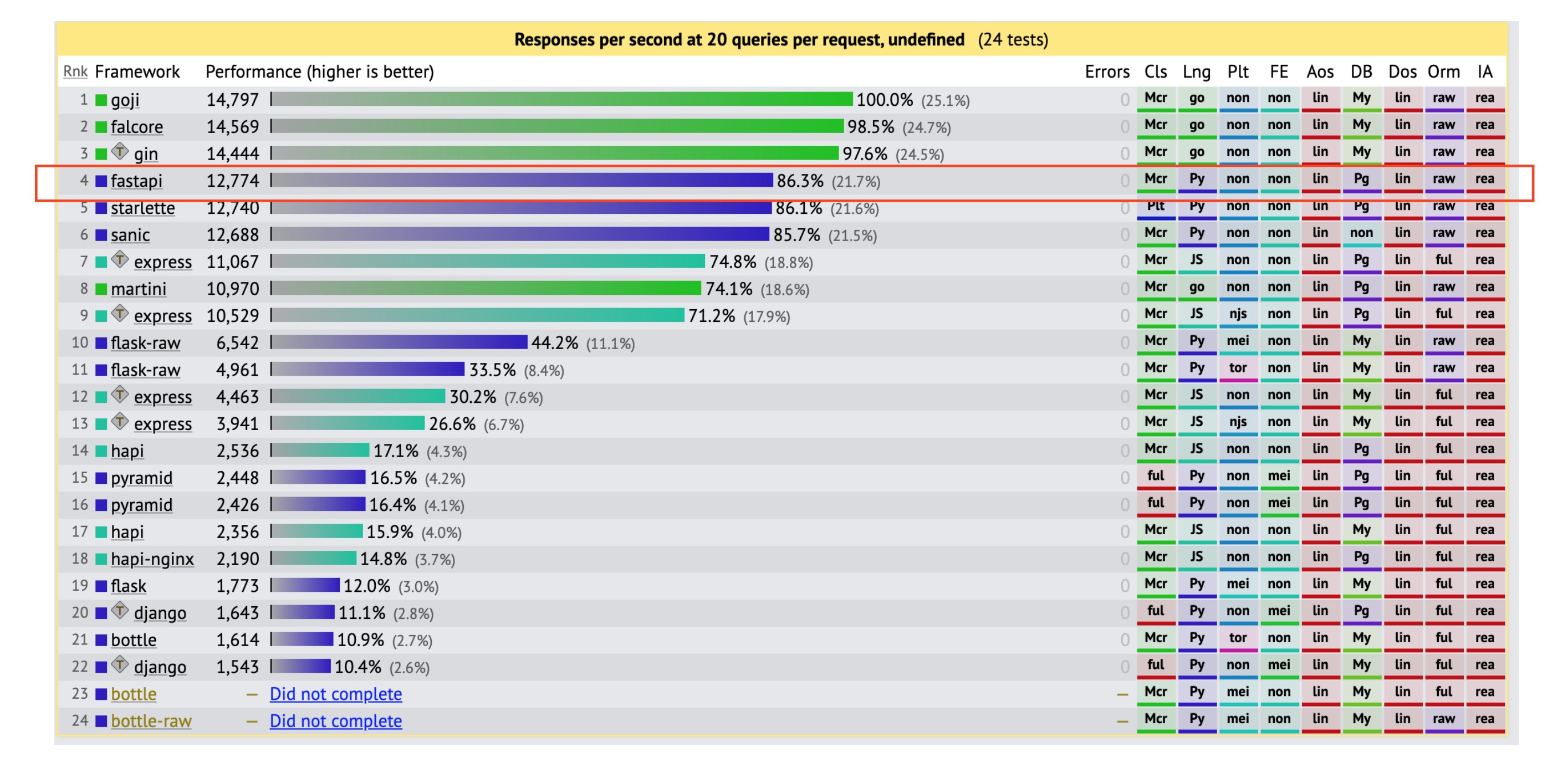
Naturally, benchmarks should be taken with a pinch of salt, have a look at the source of these
Async IO is a great fit for IO-bound network code (which is most APIs), where you have to wait for something, for example:
- Fetching data from other APIs
- Receiving data over a network (e.g. from a client browser)
- Querying a database
- Reading the contents of a file
Async IO is not threading, nor is it multiprocessing. In fact, async IO is a single-threaded, single-process design: it uses cooperative multitasking. For more on the trade-offs of these different approaches see this great article.
If you’re still confused check out two great analogies:
In any Python program that uses asyncio, there will be an asycio event loop
The event loop is the core of every asyncio application. Event loops run asynchronous tasks and callbacks, perform network IO operations, and run subprocesses.
With basic examples, you’ll see this kind of code:
async def main():
await asyncio.sleep(1)
print('hello')
asyncio.run(main())When you see a function defined with async def it is a special function called a coroutine.
The reason why coroutines are special is that they can be paused internally, allowing the program to execute them in increments
via multiple entry points for suspending and resuming execution. This is in contrast to normal functions which only
have one entry point for execution.
Where you see the await keyword, this is instructing the program that this is a “suspendable point” in the coroutine.
It’s a way for you to tell Python “this bit might take a while, feel free to go and do something else”.
In the above code snippet, asyncio.run is the
highlevel API for executing the coroutine and also managing the asyncio event loop.
With FastAPI (and uvicorn our ASGI server), the management of the event loop is taken care of for you. This means that the main things we need to concern ourselves with are:
- Declaring API path operation endpoint functions (and any downstream functions they depend on) as coroutines via
async defwhere appropriate. If you do this wrong, FastAPI is still able to handle it, you just won’t get the performance benefits. - Declaring particular points as awaitable via the
awaitkeyword within the coroutines.
Let’s try it out!
Practical Section - Async IO Path Operations
Let’s take a look at the new additions to the app directory in part-9:
├── app
│ ├── __init__.py
│ ├── api
│ │ ├── __init__.py
│ │ ├── api_v1
│ │ │ ├── __init__.py
│ │ │ ├── api.py
│ │ │ └── endpoints
│ │ │ ├── __init__.py
│ │ │ └── recipe.py ----> UPDATED
│ │ └── deps.py
│ ├── backend_pre_start.py
│ ├── core
│ │ ├── __init__.py
│ │ └── config.py
│ ├── crud
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── crud_recipe.py
│ │ └── crud_user.py
│ ├── db
│ │ ├── __init__.py
│ │ ├── base.py
│ │ ├── base_class.py
│ │ ├── init_db.py
│ │ └── session.py
│ ├── initial_data.py
│ ├── main.py ----> UPDATED
│ ├── models
│ │ ├── __init__.py
│ │ ├── recipe.py
│ │ └── user.py
│ ├── schemas
│ │ ├── __init__.py
│ │ ├── recipe.py
│ │ └── user.py
│ └── templates
│ └── index.html
├── poetry.lock
├── prestart.sh
├── pyproject.toml
├── README.md
└── run.sh
To follow along:
- Clone the tutorial project repo
cdinto part-9pip install poetry(if you don’t have it already)poetry installpoetry run ./prestart.sh(sets up a new DB in this directory)poetry run ./run.sh- Open http://localhost:8001
You should be greeted by our usual server-side rendered HTML:
So far no change. Now navigate to the interactive swagger UI docs at http://localhost:8001/docs. You’ll
notice that the recipe REST API endpoints now include:
/api/v1/recipes/ideas/async/api/v1/recipes/ideas
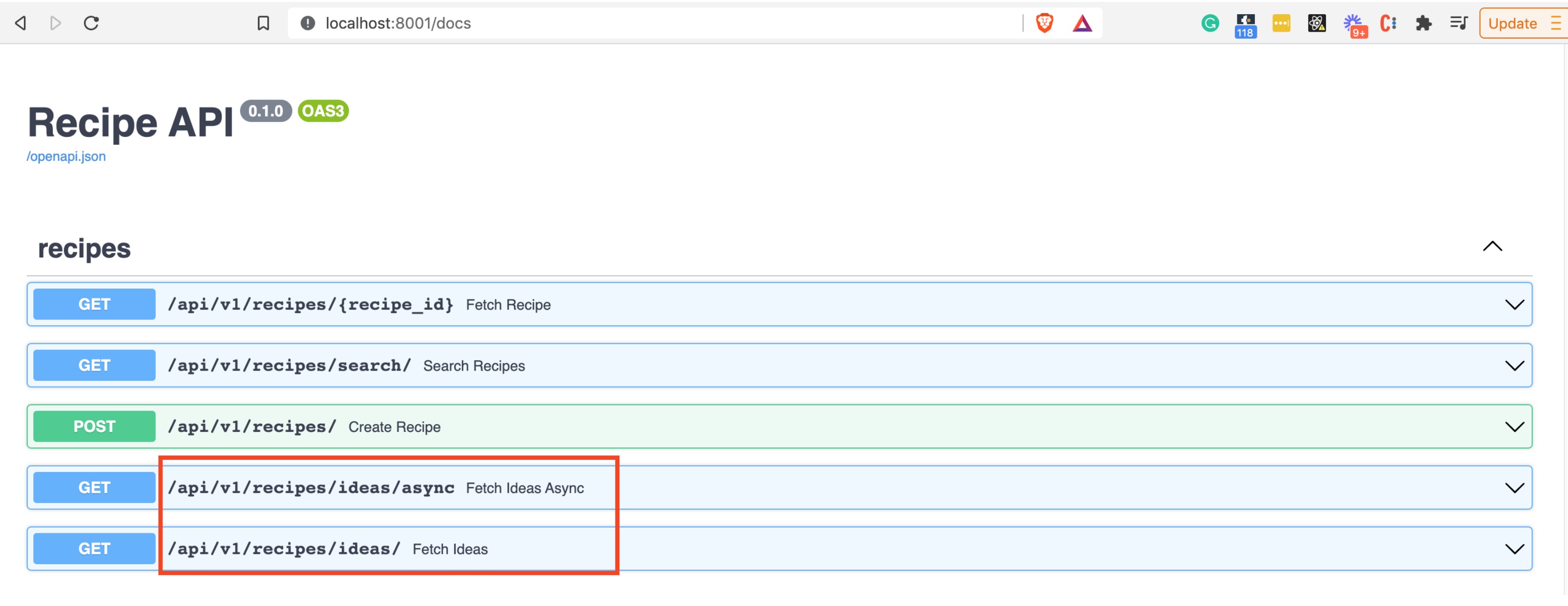
These are two new endpoints that both do the same thing: fetch top recipes from three different subreddits and return them to the client. Obviously, this is for learning purposes, but you can imagine a scenario where our imaginary recipe API business wanted to offer API users a “recipe idea” feature.
Let’s have a look at the code for the non-async new endpoint:
app/api_v1/endpoints/recipe py file
import httpx # 1
# skipping...
def get_reddit_top(subreddit: str, data: dict) -> None:
response = httpx.get(
f"https://www.reddit.com/r/{subreddit}/top.json?sort=top&t=day&limit=5",
headers={"User-agent": "recipe bot 0.1"},
) # 2
subreddit_recipes = response.json()
subreddit_data = []
for entry in subreddit_recipes["data"]["children"]:
score = entry["data"]["score"]
title = entry["data"]["title"]
link = entry["data"]["url"]
subreddit_data.append(f"{str(score)}: {title} ({link})")
data[subreddit] = subreddit_data
@router.get("/ideas/")
def fetch_ideas() -> dict:
data: dict = {} # 3
get_reddit_top("recipes", data)
get_reddit_top("easyrecipes", data)
get_reddit_top("TopSecretRecipes", data)
return data
# skipping...Let’s break this down:
- We’re introducing a new library called
httpx. This is an HTTP client similar to therequestslibrary which you might be more familiar with. However, unlikerequests,httpxcan handle async calls, so we use it here. - We make a
GETHTTP call to reddit, grabbing the first 5 results. - The
datadictionary is updated in each call toget_reddit_top, and then returned at the end of the path operation.
Once you get your head around the reddit API calls, this sort of code should be familiar (if it’s not, backtrack a few sections in the tutorial series).
Now let’s look at the async equivalent endpoint:
app/api_v1/endpoints/recipe.py
import httpx
import asyncio # 1
# skipping...
async def get_reddit_top_async(subreddit: str, data: dict) -> None: # 2
async with httpx.AsyncClient() as client: # 3
response = await client.get( # 4
f"https://www.reddit.com/r/{subreddit}/top.json?sort=top&t=day&limit=5",
headers={"User-agent": "recipe bot 0.1"},
)
subreddit_recipes = response.json()
subreddit_data = []
for entry in subreddit_recipes["data"]["children"]:
score = entry["data"]["score"]
title = entry["data"]["title"]
link = entry["data"]["url"]
subreddit_data.append(f"{str(score)}: {title} ({link})")
data[subreddit] = subreddit_data
@router.get("/ideas/async")
async def fetch_ideas_async() -> dict:
data: dict = {}
await asyncio.gather( # 5
get_reddit_top_async("recipes", data),
get_reddit_top_async("easyrecipes", data),
get_reddit_top_async("TopSecretRecipes", data),
)
return data
# skipping...OK, let’s break this down:
- Although it isn’t always necessary, in this case we do need to import
asyncio - Notice the
get_reddit_top_asyncfunction is declared with theasynckeyword, defining it as a coroutine. async with httpx.AsyncClient()is thehttpxcontext manager for making async HTTP calls.- Each GET request is made with the
awaitkeyword, telling the Python that this is a point where it can suspend execution to go and do something else. - We use the
asyncio.gatherto run a sequence of awaitable objects (i.e. our coroutines) concurrently.
Point 5 isn’t shown explicitly in the FastAPI docs, since it’s to do with usage of asyncio rather than FastAPI. But
it’s easy to miss that you need this kind of extra code to really leverage concurrency.
In order to test our new endpoints, we’ll add a small bit of middleware to track response times. Middleware is a function that works on every request before it is processed by any specific path operation. We’ll look at more Middleware later in the tutorial series. For now you just need to know that it will time our new endpoints.
In app/main.py
# skipping...
@app.middleware("http")
async def add_process_time_header(request: Request, call_next):
start_time = time.time()
response = await call_next(request)
process_time = time.time() - start_time
response.headers["X-Process-Time"] = str(process_time)
return response
# skipping...Great! Now let’s open up our interactive API documentation at http://localhost:8001/docs and try out the new endpoints:

When you click the execute button, you’ll see a new addition in the response headers:
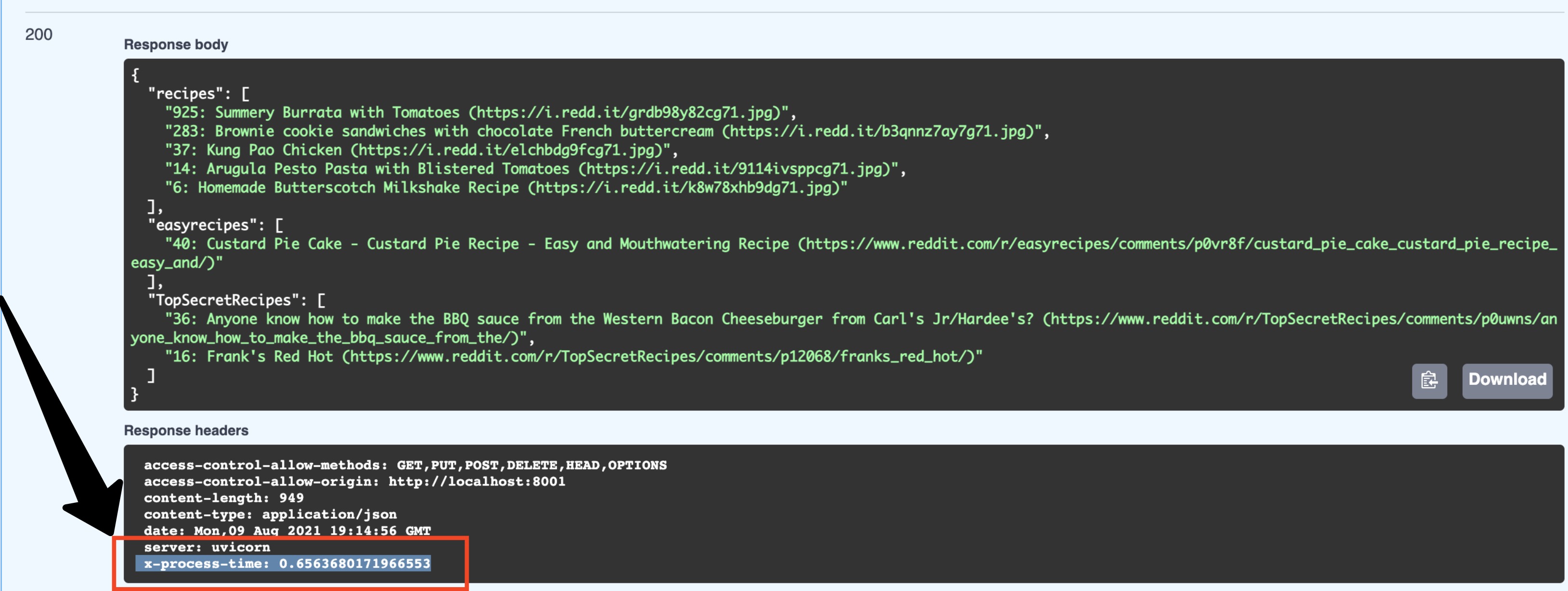
Notice the x-process-time header (highlighted in the screengrab above). This is how we can easily compare the times
of the two endpoints. If you try both /api/v1/recipes/ideas/async and /api/v1/recipes/ideas, you should see that
the async endpoint is 2-3X faster.
We’ve just tapped into FastAPI’s high-performance capabilities!
Notes on Async IO and Third Party Dependencies like SQLAlchemy
After the euphoria of the previous section, you might be tempted to think you can just plonk async and awaits for
any and every IO call to get a performance speed up. One obvious place to assume this is with database queries (another
classic IO operation).
Not so fast I’m afraid.
Every library that you attempt to await needs to support async IO. Many do not. SQLAlchemy only introduced this
compatibility in version 1.4 and there are a lot
of new things to factor in like:
- DB drivers which support async queries
- New query syntax
- Creating the engine & session with new async methods
We’ll be looking at this later in the tutorial series in the advanced part.
Continue Learning FastAPI
Phew! That was quite a theory-heavy one. Next, we’ll switch it up and look at auth with JSON web tokens (JWT).